picture link fix and error correct.
Change-Id: I0b5a61d1e8408ba044952ab0bf38e74125b6d244
This commit is contained in:
parent
d6f5700a7e
commit
496188f902
@ -92,7 +92,7 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
|
||||
  在中国移动《算力网络白皮书》中,将算力网络体系划分成了3层,包含运营服务层、编排管理层、算网基础设施层。其中,算网基础设施层主要提供泛在的算力基础设施(用以满足中心级、边缘级、现场级的算力需求)和高效的网络基础设施(用以支撑用户灵活通过网络接入泛在算力);编排管理层是算力网络的调度中心,算网大脑是编排管理层的核心,整体向下实现对算网资源的统一管理、统一编排、智能调度、全局优化等,向上提供算网调度能力接口,支撑算网络多的多元化服务;服务运营层是面向用户的服务层,一方面可基于底层算网资源形成多种业务向用户提供算网服务,另一方面可与其他算力供应商协同构建统一的交易服务平台,提供“算力电商”等新型商业模式。
|
||||
|
||||

|
||||

|
||||
|
||||
(如想了解更多图谱中具体的技术领域,可参见中国移动《算力网络白皮书》、《算力网络技术白皮书》)
|
||||
|
||||
@ -111,7 +111,7 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| 场景描述 | 随着全社会全行业数字化转型的不断变革,云上办公变得越来越普遍。云上办公具有资源随选,方便快捷,移动性强等特点,受到大中型企业的青睐。云桌面是一种具体的实现方式。通过集中管理企业员工所需要的办公计算资源,采用规模化,数字化的手段,可以减少企业IT运营和成本支出,提高生产效率。由于企业有遍布全国乃至全球的分支机构,既有对算力的要求,也有对网络的要求。因此,此场景可以认为是算力网络的一个典型场景。|
|
||||
| 当前解决方案及Gap分析 | 传统云桌面解决方案通常根据员工所在地理位置静态分配一个云桌面,不考虑网络状态和员工移动到另一个地方,是否还能得到跟本地一致体验。企业整体IT资源利用率也无法达到最优。|
|
||||
| 算力网络需求推导 | **基于算网融合下的VDI云桌面需求:** <br> 1. 用户使用云桌面时,根据云桌面的用途对时延和带宽有不同的要求。例如办公类的云桌面一般要求时延小于30ms,带宽2M左右。如果是仿真设计类的云桌面则时延更低,带宽要更高。因此,VDI场景需要算力网络在选择VDI资源池的时候能根据用户的云桌面类型计算出合适时延和带宽的网络路径。要求算力网络具有网络调度能力。 <br> 2. 另外根据云桌面类型的不同,其要求的计算/存储资源也会有所不同。例如设计仿真类的云桌面需要带GPU、需要若干CPU核及若干内存等等。因此,VDI场景还需要算力网络在选择VDI资源池的时候能根据云桌面类型匹配合适的硬件形态和容量。要求算力网络具有计算调度能力。 <br> 3. 用户可能随时出差或外派,需要算力网络能根据用户新的位置调整云桌面资源,执行云桌面迁移或备份,保证用户一致性体验。企业整体IT资源利用率达到最优。|
|
||||
| 参考实现与流程 | 此场景下需要VDI管理系统(下文称VDI Center)和算网大脑联动。系统示意图: <br>  <br> 具体工作流程: <br> 1. 企业在不同地理位置部署云桌面服务器资源池。可以自建私有云数据中心,也可以使用公有云服务。VDI Center为一个集中的VDI云桌面管理系统。VDI Center向算网大脑报告所有计算资源信息。算网大脑同时维护企业上网接入POP点(网PE)和IT资源中心POP点(云PE)信息。 <br> 2. 用户需要申请云桌面,携带网络SLA要求、计算资源要求向VDI Center提出申请。 <br> 3. VDI Center向算网大脑请求合适的资源池,并计算从用户分支站点到资源池的网络路径,满足SLA要求。算网大脑返回资源池信息,并预留建立路径。 <br> 4. VDI Center拿到最优的资源池信息后,通过该资源池的云管平台申请计算资源。并将计算资源的信息返回用户。 <br> 5. 用户通过之前建立的路径访问云桌面。 <br> 6. 用户出差到其他区域,发起云桌面迁移请求。 <br> 7. VDI Center重新向算网大脑请求新的合适的资源池。算网大脑重新优化资源池,并建立新路径。返回VDI Center。 <br> 8. VDI Center发现新的资源池,发起虚机迁移过程。 <br> 9. 用户通过新路径访问新的云桌面。|
|
||||
| 参考实现与流程 | 此场景下需要VDI管理系统(下文称VDI Center)和算网大脑联动。系统示意图: <br> 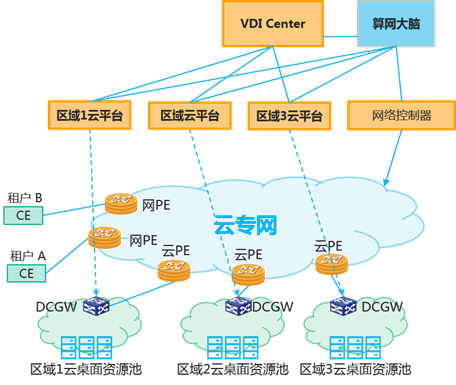 <br> 具体工作流程: <br> 1. 企业在不同地理位置部署云桌面服务器资源池。可以自建私有云数据中心,也可以使用公有云服务。VDI Center为一个集中的VDI云桌面管理系统。VDI Center向算网大脑报告所有计算资源信息。算网大脑同时维护企业上网接入POP点(网PE)和IT资源中心POP点(云PE)信息。 <br> 2. 用户需要申请云桌面,携带网络SLA要求、计算资源要求向VDI Center提出申请。 <br> 3. VDI Center向算网大脑请求合适的资源池,并计算从用户分支站点到资源池的网络路径,满足SLA要求。算网大脑返回资源池信息,并预留建立路径。 <br> 4. VDI Center拿到最优的资源池信息后,通过该资源池的云管平台申请计算资源。并将计算资源的信息返回用户。 <br> 5. 用户通过之前建立的路径访问云桌面。 <br> 6. 用户出差到其他区域,发起云桌面迁移请求。 <br> 7. VDI Center重新向算网大脑请求新的合适的资源池。算网大脑重新优化资源池,并建立新路径。返回VDI Center。 <br> 8. VDI Center发现新的资源池,发起虚机迁移过程。 <br> 9. 用户通过新路径访问新的云桌面。|
|
||||
| 技术发展及开源工作建议 | 建议增加对算力网络编排管理层中算网大脑的研究: <br> 1. 综合计算信息和网络信息,有一套多目标优化的调度算法。(VDI场景只需要维护IaaS底层资源信息,不关心PaaS/SaaS类算力服务信息。) <br> 2. 能够管理多种不同形态的资源,并建立统一的度量衡。|
|
||||
|
||||
|
||||
@ -122,7 +122,7 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
|:----|:----|
|
||||
| 贡献者 | 中国移动美研所-潘伟森 |
|
||||
| 应用名称 | 基于AI的算力网络流量控制与算力匹配 |
|
||||
| 场景描述 | 1. 算力网络集成了分布于不同地理位置的分布式和泛在化的计算能力,其来源包括了各种计算设备如云计算节点、边缘计算节点、终端设备、网络设备等, 在算力网络环境中的计算任务量大、类型多样,包括数据分析、AI推理、图形渲染等各类计算任务,在这种情况下,传统的流量控制策略可能无法有效处理任务的多样性和量级,可能导致计算资源的浪费、计算任务的延迟、服务质量下降等问题。为了解决这些问题,可以采用基于AI的流量控制与算力匹配,通过收集大量的网络流量数据、设备状态数据和任务需求数据,使用深度学习算法训练AI模型。模型能够学习到网络流量和计算任务的模式,预测未来的流量变化和任务需求,以及设备的计算能力,并根据这些信息实时调整流量控制策略与算力匹配策略。 <br> 2. 在AI的帮助下,运营商能够更有效地管理流量和算力,减少网络拥堵,提高计算资源的利用率,降低计算任务的延迟,提高服务质量。例如,在预测到大量的数据分析任务将要到来时,AI系统可以提前调整网络配置,优先将计算资源分配给这些任务,以满足需求。在预测到计算设备的能力不足以处理即将到来的任务时,AI系统可以提前调整流量控制策略,将部分任务重定向到其他设备,以防止拥堵。 <br> 3. 基于AI的算力网络流量控制与算力匹配将大规模的算力网络带来了显著的性能提升,使得运营商能够更好地管理计算资源,满足各类计算任务的需求。 <br> |
|
||||
| 场景描述 | 1. 算力网络集成了分布于不同地理位置的分布式和泛在化的计算能力,其来源包括了各种计算设备如云计算节点、边缘计算节点、终端设备、网络设备等, 在算力网络环境中的计算任务量大、类型多样,包括数据分析、AI推理、图形渲染等各类计算任务,在这种情况下,传统的流量控制策略可能无法有效处理任务的多样性和量级,可能导致计算资源的浪费、计算任务的延迟、服务质量下降等问题。为了解决这些问题,可以采用基于AI的流量控制与算力匹配,通过收集大量的网络流量数据、设备状态数据和任务需求数据,使用深度学习算法训练AI模型。模型能够学习到网络流量和计算任务的模式,预测未来的流量变化和任务需求,以及设备的计算能力,并根据这些信息实时调整流量控制策略与算力匹配策略。 <br> 2. 在AI的帮助下,运营商能够更有效地管理流量和算力,减少网络拥堵,提高计算资源的利用率,降低计算任务的延迟,提高服务质量。例如,在预测到大量的数据分析任务将要到来时,AI系统可以提前调整网络配置,优先将计算资源分配给这些任务,以满足需求。在预测到计算设备的能力不足以处理即将到来的任务时,AI系统可以提前调整流量控制策略,将部分任务重定向到其他设备,以防止拥堵。 <br> 3. 基于AI的算力网络流量控制与算力匹配将大规模的算力网络带来了显著的性能提升,使得运营商能够更好地管理计算资源,满足各类计算任务的需求。 <br> |
|
||||
| 当前解决方案及Gap分析 | 基于AI的算力网络流量控制与算力匹配通过人工智能技术,可以实时监测算力网络状态,动态预测网络流量需求,自动优化算力网络资源分配和负载均衡。还能通过深度学习算法,不断学习和改进自己的流量控制策略,使其更加适应复杂和多变的网络环境。 <br> Gap分析: <br> 1. 动态性与自适应性:传统的流量控制方法往往较为静态,难以适应未来算力网络环境的快速变化。而基于AI的流量控制与算力匹配则具有很强的动态性和自适应性,可以根据实时的网络状态和预测的流量需求,动态调整流量控制策略和算力分配策略。 <br> 2. 学习与改进:传统的流量控制方法往往缺乏自我学习和改进的能力。而基于AI的流量控制与算力匹配则可以通过深度学习算法,不断学习和改进自己的流量控制与算力匹配策略,使其更加适应复杂和多变的网络环境。 <br> 3. 对未来技术的适应性:随着算力网络及相关应用的快速发展,未来的算力网络环境和流量需求可能会更加复杂和多变。因此,基于AI的流量控制与算力引导对于未来算力网络和相关应用具有更好的适应性和前瞻性。|
|
||||
| 算力网络需求推导 | 在算力网络中,流量控制和算力合理的匹配对于确保高效运行和资源优化至关重要。这需要一种能够实时、动态地调整流量控制策略和算力匹配的系统。基于人工智能的流量控制和算力匹配有望满足这种需求。以下是具体的需求推导过程: <br> 1. 高效率的资源利用:在大规模、分布式的算力网络中,资源的使用效率直接影响到整个网络的运行效率和成本。通过AI技术,能够更精准地预测和调度流量,使得资源得到更合理、更高效的利用。 <br> 2. 动态调整和优化:网络流量和任务需求可能会随时间、应用和用户行为发生变化,这就需要流量控制策略能够实时响应这些变化。AI技术可以通过实时学习和预测,实现动态调整和优化流量控制策略,并合理的匹配到最优的算力。 <br> 3. 负载均衡:在面对流量突发变化或任务需求变化时,保持网络负载均衡至关重要。AI技术可以通过实时监控和预测网络状态,动态调整流量和任务分布,保持负载均衡。 <br> 4. 服务质量保证:在保证服务质量方面,AI技术可以根据预测的网络状态和任务需求,优先满足重要任务和服务的需求,从而提高服务质量。 <br> 5. 自动化管理:通过自动学习和更新规则,AI技术可以减轻算力网络管理的工作负担,实现更高程度的自动化管理。 <br> 因此,引入基于AI的流量控制和算力引导,不仅可以提高算力网络的运行效率和服务质量,还可以实现更高程度的自动化管理,这是符合算力网络发展需求的。|
|
||||
| 参考实现与流程 | 1. 数据收集:收集算力网络中的历史数据,如各节点的算力利用率、任务执行时间、网络延迟等,以此作为训练AI模型的数据基础。 <br> 2. 数据预处理:对收集到的数据进行预处理,包括数据清洗、格式转换、特征提取等。 <br> 3. 模型选择训练:根据算力网络的特点和需求,选择合适的AI模型(如深度学习模型、强化学习模型等)进行训练。训练的目标是让AI模型学会如何在各种条件下进行最优的流量控制和算力分配。 <br> 4、模型测试与优化:在模拟环境或实际环境中测试训练好的AI模型,根据测试结果进行模型的调整和优化。 <br> 5、模型部署:优化好的AI模型部署到算力网络中,根据实时网络状态和任务需求进行流量控制和算力引导。 <br> 6、 实时调整:模型在部署后需要根据实时收集到的网络状态和任务需求数据进行动态调整和优化。 <br> 7、模型更新:根据网络运行情况和模型性能,定期对模型进行更新和优化。 <br> 8、持续监测和调整:在模型部署后,需持续监测网络状态和任务执行情况,根据需要对AI模型进行调整,并周期性地重新训练模型以应对网络环境的变化。 |
|
||||
@ -136,9 +136,9 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| 贡献者 | 浪潮-耿晓巧 |
|
||||
| 应用名称 |面向视频应用的算网一体调度|
|
||||
| 场景描述 | 基于轨道交通等智能视频场景,以客户业务为中心,构建算网一体的任务式服务调度能力,感知并解析用户对时延、成本等的业务需求,进行计算、存储等资源的协同调度和分配,并实现调度策略的动态优化,实现向客户提供按需、灵活、智能的算力网络服务,同时广泛适配各类行业应用场景,赋能视频业务智能转型。 |
|
||||
| 当前解决方案及Gap分析 | 1.算网资源异构、泛在,业务复杂且性能要求较高,传统解决方案中网、云、业务存在协同壁垒,无法满足各类场景调度需求。 <br> 2.业务高峰期数据传输量大、网络负载高,导致高时延,影响视频业务服务质量,对视频调度方案的优化提出了更高的要求与挑战。 <br>  <br> 3、视频业务智能化不足,未形成全流程自动化监管与预警处置闭环。|
|
||||
| 当前解决方案及Gap分析 | 1.算网资源异构、泛在,业务复杂且性能要求较高,传统解决方案中网、云、业务存在协同壁垒,无法满足各类场景调度需求。 <br> 2.业务高峰期数据传输量大、网络负载高,导致高时延,影响视频业务服务质量,对视频调度方案的优化提出了更高的要求与挑战。 <br>  <br> 3、视频业务智能化不足,未形成全流程自动化监管与预警处置闭环。|
|
||||
| 算力网络需求推导 | 1.基于对资源状态和业务需求的感知度量,结合优化算法,在不同时间段和不同站点进行算力资源的优化调度和分配,构建面向行业应用的算网调度协同技术体系。 <br> 2.面向各类视频用户提供任务式服务(最优路径、最近距离、最低成本),及AI智能视频服务。 |
|
||||
| 参考实现与流程 |  <br> 1.感知、采集、分析底层算力资源、网络资源和存储资源,以及感知用户业务类型,和对时延、传输数据量、上传流量等的需求。 <br> 2.面向用户对时延、成本等的业务需求,结合系统整体建模、业务规则分析、优化策略求解以及系统模块对接等,提供分时潮汐调度、跨区域调度和智能编排调度等能力。 <br> 3.实时评估当前调度策略是否能够满足用户业务需求,将相关指标反馈给智能调度模块,智能调度模块基于此对调度策略进行动态优化调整。 <br> 4.将视频处理、AI推理、数据处理等处理任务灵活下发到相关计算资源中,提供视频数据自动备份、AI训练、AI视频实时推理等智能视频作业服务。 |
|
||||
| 参考实现与流程 | 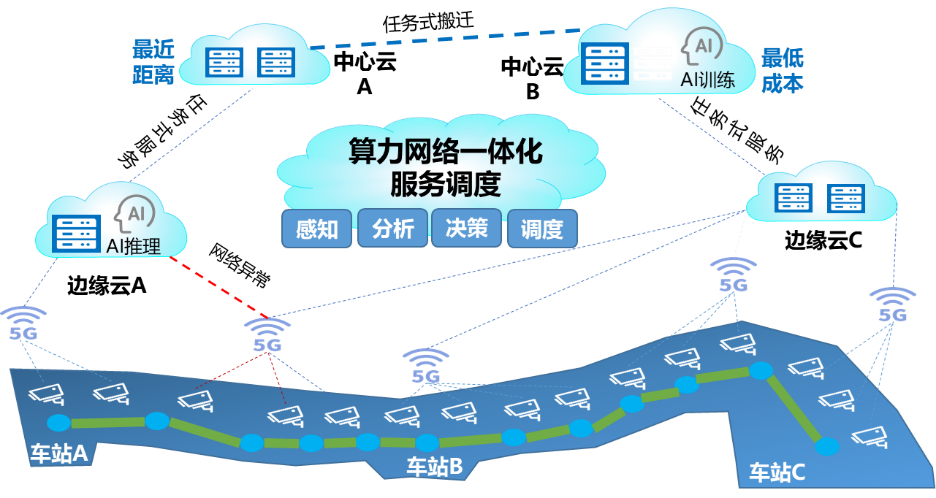 <br> 1.感知、采集、分析底层算力资源、网络资源和存储资源,以及感知用户业务类型,和对时延、传输数据量、上传流量等的需求。 <br> 2.面向用户对时延、成本等的业务需求,结合系统整体建模、业务规则分析、优化策略求解以及系统模块对接等,提供分时潮汐调度、跨区域调度和智能编排调度等能力。 <br> 3.实时评估当前调度策略是否能够满足用户业务需求,将相关指标反馈给智能调度模块,智能调度模块基于此对调度策略进行动态优化调整。 <br> 4.将视频处理、AI推理、数据处理等处理任务灵活下发到相关计算资源中,提供视频数据自动备份、AI训练、AI视频实时推理等智能视频作业服务。 |
|
||||
| 技术发展及开源工作建议 | 1.将AI智能视频能力与算力网络相结合,满足行业场景多样化需求。 <br> 2.建议展开算网资源度量相关研究,为算力网络提供统一资源模板。|
|
||||
|
||||
## 4.4 基于多方安全计算的借贷风险评估
|
||||
@ -147,10 +147,10 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
|:----|:----|
|
||||
| 贡献者 | 亚信-郭建超 |
|
||||
| 应用名称 | 隐私计算 |
|
||||
| 场景描述 |当个人/企业向银行进行贷款申请时,银行需评估借贷风险,排查用户多头借贷及超额借贷的风险。通过搭建的隐私计算平台,运用隐私查询、多方联合统计,联合多家银行,在贷前对用户各银行的借贷总额进行联合统计。银行收到联合统计结果后,决定是否向用户发放贷款。 <br> 在该场景下,隐匿查询服务和多方联合统计服务与算力网络高度相关: <br> 1. 隐匿查询服务:通过隐私计算,查询方可隐藏被查询对象关键词或客户ID信息,数据提供方提供匹配的查询结果却无法获知具体对应哪个查询对象,能杜绝数据缓存、数据泄漏、数据贩卖的可能性。 <br> 2. 多方联合统计服务:通过隐私计算,可使多个非互信主体在数据相互保密的前提下进行高效数据融合计算,达到“数据可用不可见”,最终实现数据的所有权和数据使用权相互分离。 <br> |
|
||||
| 场景描述 |当个人/企业向银行进行贷款申请时,银行需评估借贷风险,排查用户多头借贷及超额借贷的风险。通过搭建的隐私计算平台,运用隐私查询、多方联合统计,联合多家银行,在贷前对用户各银行的借贷总额进行联合统计。银行收到联合统计结果后,决定是否向用户发放贷款。 <br> 在该场景下,隐匿查询服务和多方联合统计服务与算力网络高度相关: <br> 1. 隐匿查询服务:通过隐私计算,查询方可隐藏被查询对象关键词或客户ID信息,数据提供方提供匹配的查询结果却无法获知具体对应哪个查询对象,能杜绝数据缓存、数据泄漏、数据贩卖的可能性。 <br> 2. 多方联合统计服务:通过隐私计算,可使多个非互信主体在数据相互保密的前提下进行高效数据融合计算,达到“数据可用不可见”,最终实现数据的所有权和数据使用权相互分离。 <br> 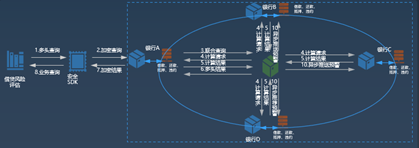|
|
||||
| 当前解决方案及Gap分析 | |
|
||||
| 算力网络需求推导 | “不解决算力和通信问题,隐私计算的大规模应用将无从谈起”,隐私计算技术对算力要求和依赖度很高,面对越来越多的数据,分布式模型需要大量通信网络支撑,对于算力,需要按照服务的全场景情况对算力进行快速智能分配及实时调度。 <br> 1. 计算密集型:采用大量密文计算,加密后的数据计算将会产生大量的算力开销,单次模型训练与迭代的耗时将会呈现指数级增长。 <br> 2. 网络密集型:隐私计算模型分布多个计算方,应用往往需要频繁通信以交换中间结果,加之以密态来传递中间结果。 <br> 3. 存储密集型:数据计算过程和结果对存储有大量的存储需求,需要及时提供存储能力。 除了资源维度上的要求,该场景对于算网融合调度也提出了更高的要求。该场景的部署采用 “联盟端+管理端”的方式,采用分布式密文计算架构,进行云及本地部署,同时可灵活投入硬件与计算资源,快速实施部署和升级。在该场景中,隐匿查询服务和多方联合统计服务涉及到多地算力节点的协同计算、节点之间数据密文以及加密算法的协同,需要算力网络具备算力和网络的协同调度能力,满足网络传输需求的同时,综合考虑传输时延、计算节点的任务执行时延,杜绝算力短板引发的“木桶效应”。同时,需要算力网络具备动态的资源调度能力,能够实时满足业务调度的需求。 <br> |
|
||||
| 参考实现与流程 |  <br> 1. 银行方发起联合模型训练方案业务请求; <br> 2. 算网运营交易中心向算网大脑提出业务请求; <br> 3. 算网大脑分析业务请求(可能包含位置、资源需求等) 查询可用节点及路径(专线/专网),回复算网运营中心可选方案; <br> 4. 算网运营中心答复资源需求方方案及价格信息; <br> 5. 资源需求方答复确认方案; <br> 6. 算网运营中心将选择的方案发松给算网大脑; <br> 7. 算网大脑进行方案自验证(基于数字孪生技术或其它仿真技术); <br> 8. 向算网运营交易中心答复方案自验证情况(算力、网络、资源等信息确认) ; <br> 9.算网运营中心确认方案; <br> 10. 算网大脑向算网基础设施层发起资源开通和路径(网络)建立请求; <br> 11. 算网基础回复资源开通和路径建立; <br> 12. 业务开通回复; <br> 13. 算网运营交易中心答复资源需求方业务开通,资源需求方进行模型训练及部署后的模型推理等.|
|
||||
| 算力网络需求推导 | “不解决算力和通信问题,隐私计算的大规模应用将无从谈起”,隐私计算技术对算力要求和依赖度很高,面对越来越多的数据,分布式模型需要大量通信网络支撑,对于算力,需要按照服务的全场景情况对算力进行快速智能分配及实时调度。 <br> 1. 计算密集型:采用大量密文计算,加密后的数据计算将会产生大量的算力开销,单次模型训练与迭代的耗时将会呈现指数级增长。 <br> 2. 网络密集型:隐私计算模型分布多个计算方,应用往往需要频繁通信以交换中间结果,加之以密态来传递中间结果。 <br> 3. 存储密集型:数据计算过程和结果对存储有大量的存储需求,需要及时提供存储能力。 除了资源维度上的要求,该场景对于算网融合调度也提出了更高的要求。该场景的部署采用 “联盟端+管理端”的方式,采用分布式密文计算架构,进行云及本地部署,同时可灵活投入硬件与计算资源,快速实施部署和升级。在该场景中,隐匿查询服务和多方联合统计服务涉及到多地算力节点的协同计算、节点之间数据密文以及加密算法的协同,需要算力网络具备算力和网络的协同调度能力,满足网络传输需求的同时,综合考虑传输时延、计算节点的任务执行时延,杜绝算力短板引发的“木桶效应”。同时,需要算力网络具备动态的资源调度能力,能够实时满足业务调度的需求。 <br> |
|
||||
| 参考实现与流程 |  <br> 1. 银行方发起联合模型训练方案业务请求; <br> 2. 算网运营交易中心向算网大脑提出业务请求; <br> 3. 算网大脑分析业务请求(可能包含位置、资源需求等) 查询可用节点及路径(专线/专网),回复算网运营中心可选方案; <br> 4. 算网运营中心答复资源需求方方案及价格信息; <br> 5. 资源需求方答复确认方案; <br> 6. 算网运营中心将选择的方案发松给算网大脑; <br> 7. 算网大脑进行方案自验证(基于数字孪生技术或其它仿真技术); <br> 8. 向算网运营交易中心答复方案自验证情况(算力、网络、资源等信息确认) ; <br> 9.算网运营中心确认方案; <br> 10. 算网大脑向算网基础设施层发起资源开通和路径(网络)建立请求; <br> 11. 算网基础回复资源开通和路径建立; <br> 12. 业务开通回复; <br> 13. 算网运营交易中心答复资源需求方业务开通,资源需求方进行模型训练及部署后的模型推理等.|
|
||||
| 技术发展及开源工作建议 | |
|
||||
|
||||
## 4.5 基于算力网络的AI应用跨架构部署迁移
|
||||
@ -160,9 +160,9 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| 贡献者 | 中国移动研究院-赵奇慧 |
|
||||
| 应用名称 | / |
|
||||
| 场景描述 | 用户在向算力网络申请AI服务时,以人脸识别业务(AI推理类)为例,将提供应用名称、待处理的数据集信息(如图片传输接口、图片数量、图片大小)、倾向的检测地点、处理速率、成本约束等,由算力网络自行根据用户需求选择合适的算力集群部署人脸识别业务、完成配置并提供服务。 <br> 由于算力网络将来源各异、类型各异的算力构成一张统一的网络,凡符合用户SLA需求,具体承载该人脸识别业务并提供计算的底层算力可以有多种选择,可为英伟达GPU、Intel CPU、华为NPU、寒武纪MLU、海光DCU及众多其他智算芯片中的任意一种或多种组合。因此,AI应用在算力网络中的多种异构异厂商智算芯片上部署、运行、迁移,是算力网络的典型应用场景之一。此场景与云计算智算应用跨架构迁移场景类似。 <br> 除用户向算力网络申请AI服务外,上述场景也适合用户在算力网络中部署自研AI应用。 |
|
||||
| 当前解决方案及Gap分析 | AI应用(也即AI服务)的运行一般需要“AI框架+工具链+硬件”支撑,其中: AI框架指PaddlePaddle、Pytorch、TensorFlow等;硬件指各设备商的智算芯片;工具链是各设备商围绕各自智算芯片构建的系列软件,包含但不限于IDE、编译器、运行时、驱动等。目前,用户在模型、应用研发设计阶段就需要选择编程语言、框架模型、指定硬件后端并进行一体编译链接。如需实现AI应用在算力网络中的任意算力后端上运行,则需要针对不同的智算芯片、使用各芯片匹配的开发工具链等开发出多个版本并完成编译,然后依托芯片匹配的运行时完成部署。整体开发难度大、软件维护成本高。 <br>  |
|
||||
| 算力网络需求推导 | 1. 为简化用户开发和部署AI应用的难度,算力网络需协同AI框架、芯片及相关工具链形成支持AI应用跨架构部署运行的软件栈,面向用户屏蔽底层硬件差异,支持用户AI应用的一次开发、随处部署。 <br>  <br> 2. 算力网络需理解用户描述性SLA等需求,支持将其转换成可被云网基础设施理解的资源、网络、存储等需求,并支持形成符合用户SLA需求的多种资源组合方案。 <br> 3. 算力网络需依据统一标准对底层异构异厂商硬件进行度量,以支持算力网络针对用户描述性SLA需求计算出不同的资源组合方案。 <br> 4. 算力网络需支持监控整个算力网络状态,并根据上述计算得出的资源组合完成资源调度、应用部署等。 |
|
||||
| 参考实现与流程 | 本部分仅针对AI应用跨架构部署迁移设计的一种解决方案,也可存在其他实现与流程。 <br>  <br> 具体工作流程: <br> Pre1. 编排管理层已纳管底层算力资源池,并实时监控池内资源情况。 <br> Pre2. 算力服务商根据底层算力资源池内的资源类型准备跨架构基础镜像,并在编排管理层的中央基础镜像仓库中注册该镜像。跨架构基础镜像中至少包含跨架构runtime。该跨架构runtime可对上层业务提供统一的算力资源抽象,从而屏蔽底层硬件差异;对下可对接不同AI芯片的runtime或driver或指令集,将应用的算力抽象调用转译成芯片对应工具链的API调用或指令集调用,以便最终完成计算任务。 <br> 1. 算力网络为AI应用开发者(即用户)提供灵活可装载的本地跨架构开发环境,包含跨架构IDE(编译器、SDK等)、跨架构环境模拟器(根据用户本地底层硬件类型灵活适配,对应用模拟统一抽象的算力资源,以便完成应用调试)。 <br> 2. 用户完成AI应用开发后,通过跨架构开发环境生成可跨架构执行的业务可执行文件,并上载到算力网络编排管理层的跨架构业务可执行文件库中。 <br> 3. 用户向算力网络提出AI应用部署描述性SLA需求,编排管理层接收SLA请求。 <br> 4. 编排管理层根据多类资源统一监控数据解析SLA需求,转化成算网基础设施层可理解的资源需求,该资源需求可存在多种资源组合,在用户选择具体组合方案后,触发业务部署。 <br> 5. 业务部署过程首先完成AI应用镜像及部署文件的生成。对于镜像,将结合用户选择的底层资源类型从中央基础镜像仓库中拉取对应的跨架构基础镜像,并自动与待部署AI应用的跨架构可执行文件打包,生成完整的跨架构业务镜像,并将该完整业务镜像下发到底层资源池内的镜像仓库中。对于部署文件,将根据底层环境类型(裸机环境、容器环境、虚机环境)、解析的资源需求、镜像位置、业务配置等信息/文件生成自动部署文件(可为脚本、Helm Chart、Heat模板等)。 <br> 6. 基础设施层资源池内的编排管理组件根据部署文件、镜像等内容部署AI应用。 <br> 7. 若AI应用需迁移到其他芯片资源池(CPU、FPGA、ASIC等)中,将重复4、5、6三个步骤。 |
|
||||
| 当前解决方案及Gap分析 | AI应用(也即AI服务)的运行一般需要“AI框架+工具链+硬件”支撑,其中: AI框架指PaddlePaddle、Pytorch、TensorFlow等;硬件指各设备商的智算芯片;工具链是各设备商围绕各自智算芯片构建的系列软件,包含但不限于IDE、编译器、运行时、驱动等。目前,用户在模型、应用研发设计阶段就需要选择编程语言、框架模型、指定硬件后端并进行一体编译链接。如需实现AI应用在算力网络中的任意算力后端上运行,则需要针对不同的智算芯片、使用各芯片匹配的开发工具链等开发出多个版本并完成编译,然后依托芯片匹配的运行时完成部署。整体开发难度大、软件维护成本高。 <br> 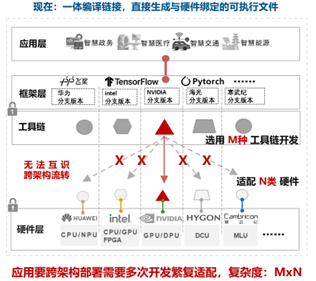 |
|
||||
| 算力网络需求推导 | 1. 为简化用户开发和部署AI应用的难度,算力网络需协同AI框架、芯片及相关工具链形成支持AI应用跨架构部署运行的软件栈,面向用户屏蔽底层硬件差异,支持用户AI应用的一次开发、随处部署。 <br> 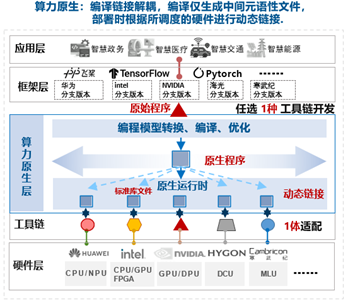 <br> 2. 算力网络需理解用户描述性SLA等需求,支持将其转换成可被云网基础设施理解的资源、网络、存储等需求,并支持形成符合用户SLA需求的多种资源组合方案。 <br> 3. 算力网络需依据统一标准对底层异构异厂商硬件进行度量,以支持算力网络针对用户描述性SLA需求计算出不同的资源组合方案。 <br> 4. 算力网络需支持监控整个算力网络状态,并根据上述计算得出的资源组合完成资源调度、应用部署等。 |
|
||||
| 参考实现与流程 | 本部分仅针对AI应用跨架构部署迁移设计的一种解决方案,也可存在其他实现与流程。 <br> 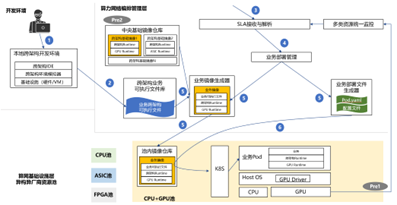 <br> 具体工作流程: <br> Pre1. 编排管理层已纳管底层算力资源池,并实时监控池内资源情况。 <br> Pre2. 算力服务商根据底层算力资源池内的资源类型准备跨架构基础镜像,并在编排管理层的中央基础镜像仓库中注册该镜像。跨架构基础镜像中至少包含跨架构runtime。该跨架构runtime可对上层业务提供统一的算力资源抽象,从而屏蔽底层硬件差异;对下可对接不同AI芯片的runtime或driver或指令集,将应用的算力抽象调用转译成芯片对应工具链的API调用或指令集调用,以便最终完成计算任务。 <br> 1. 算力网络为AI应用开发者(即用户)提供灵活可装载的本地跨架构开发环境,包含跨架构IDE(编译器、SDK等)、跨架构环境模拟器(根据用户本地底层硬件类型灵活适配,对应用模拟统一抽象的算力资源,以便完成应用调试)。 <br> 2. 用户完成AI应用开发后,通过跨架构开发环境生成可跨架构执行的业务可执行文件,并上载到算力网络编排管理层的跨架构业务可执行文件库中。 <br> 3. 用户向算力网络提出AI应用部署描述性SLA需求,编排管理层接收SLA请求。 <br> 4. 编排管理层根据多类资源统一监控数据解析SLA需求,转化成算网基础设施层可理解的资源需求,该资源需求可存在多种资源组合,在用户选择具体组合方案后,触发业务部署。 <br> 5. 业务部署过程首先完成AI应用镜像及部署文件的生成。对于镜像,将结合用户选择的底层资源类型从中央基础镜像仓库中拉取对应的跨架构基础镜像,并自动与待部署AI应用的跨架构可执行文件打包,生成完整的跨架构业务镜像,并将该完整业务镜像下发到底层资源池内的镜像仓库中。对于部署文件,将根据底层环境类型(裸机环境、容器环境、虚机环境)、解析的资源需求、镜像位置、业务配置等信息/文件生成自动部署文件(可为脚本、Helm Chart、Heat模板等)。 <br> 6. 基础设施层资源池内的编排管理组件根据部署文件、镜像等内容部署AI应用。 <br> 7. 若AI应用需迁移到其他芯片资源池(CPU、FPGA、ASIC等)中,将重复4、5、6三个步骤。 |
|
||||
| 技术发展及开源工作建议 |1. 建议增强AI应用跨架构部署迁移方案的研究,可依托CFN WG-算力原生子工作组探索参考实现。当前业界现存的阿里HALO+ODLA、Intel的 DPC++ 与LevelZero等开源方案可作为该解决方案探索的基础。 <br> 2. 建议展开算网度量的研究,以便为算力网络提供统一资源模板。 <br> 3. 建议挖掘用户描述性SLA需求,并研究该需求向具体资源需求转化的方式,详细可参见PaaS、SaaS、FaaS等服务模式。 |
|
||||
|
||||
## 4.6 算力网络裸金属管理
|
||||
@ -172,9 +172,9 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| 贡献者 | 中国移动研究院-王锦涛、中国移动研究院-赵奇慧 |
|
||||
| 应用名称 | / |
|
||||
| 场景描述 | 根据2.3节,算力网络提供资源型服务模式,支持用户直接向算力网络申请裸机、虚机、容器等资源。部分用户也因性能、安全、业务虚拟化/容器化改造难度等方面的考虑,更倾向于使用裸金属服务。传统裸金属服务资源难以灵活配置、客户需要定向适配各类驱动、发放和管理流程冗长,无论是客户体验还是管理运维手段,较虚拟化服务有较大差距。因此如何实现算力网络服务商灵活管理和运维多样基础设施、并简化用户使用裸金属是算力网络数据中心的重要需求。该场景也适用于云计算及云网融合领域。 |
|
||||
| 当前解决方案及Gap分析 | 对算力网络服务商而言,在传统的裸机发放流程中,在Inpection阶段需要手动配置网络,在provisioning和tenant阶段需要多次网络切换、节点安装和重启操作,整体流程复杂冗长,与虚拟机发放流程差异较大。对于用户而言,网卡数量和存储规格固定,无法满足不同用户的差异化网卡及存储需求;此外裸金属网卡驱动及存储客户端等均对用户可见,需要用户进行定向适配,进一步增加用户使用裸金属难度,同时块存储网络暴露在客户操作系统也存在安全风险。 <br> |
|
||||
| 当前解决方案及Gap分析 | 对算力网络服务商而言,在传统的裸机发放流程中,在Inpection阶段需要手动配置网络,在provisioning和tenant阶段需要多次网络切换、节点安装和重启操作,整体流程复杂冗长,与虚拟机发放流程差异较大。对于用户而言,网卡数量和存储规格固定,无法满足不同用户的差异化网卡及存储需求;此外裸金属网卡驱动及存储客户端等均对用户可见,需要用户进行定向适配,进一步增加用户使用裸金属难度,同时块存储网络暴露在客户操作系统也存在安全风险。 <br> |
|
||||
| 算力网络需求推导 | 算力网络实现与虚拟机类似的便捷裸金属管理及发放和管理: <br> 1. 裸金属服务器全自动化发放,通过控制台自助申请,无需人工介入,即可完成自动化镜像安装、网络配置、云盘挂载等功能; <br> 2. 完全兼容虚拟化平台云盘系统,使用云盘启动,免操作系统安装,进行云硬盘的挂载和卸载,满足弹性存储的要求,同时兼容虚拟机镜像系统; <br> 3. 兼容虚拟机VPC网络,实现裸金属服务器和虚拟机网络互通,支持自定义网络实现裸金属服务器之间互通,实现灵活组网。 |
|
||||
| 参考实现与流程 |  <br> 在裸金属服务器配置DPU卡,裸金属实例的网络端口和磁盘设备全部由DPU提供。DPU上运行了云平台的管理、网络和存储相关的组件,管理模块负责裸金属实例生命周期的管理,网络模块负责裸金属虚拟网口的实现和网络流量的转发,存储模块负责裸金属云盘的实现和存储网络协议栈的终结。在DPU场景下,裸金属的发放和管理流程如下: <br> 1. 通过云平台API或UI界面选择裸金属规格,创建裸金属实例; <br> 2. 云平台conductor组件初始化裸金属实例化流程,调用DPU上运行的管理模块,完成裸金属实例的配置; <br> 3. 云平台创建虚拟网口,在DPU上实现虚拟网口后端的初始化,裸金属在启动之后通过标准virtio驱动扫描到网口设备;同时将网口信息同步给SDN控制器,SDN控制器将流表下发到裸金属节点DPU上的vSwitch上,实现裸金属与其他实例的网络互通; <br> 4. 云平台创建云盘设备,通过iSCSI等存储网络协议栈在DPU上对接远端块存储系统,将远端卷设备抽象为标准SPDK bdev块设备,并通过NVMe/virtio-blk等后端提供给裸金属实例作为磁盘设备。|
|
||||
| 参考实现与流程 |  <br> 在裸金属服务器配置DPU卡,裸金属实例的网络端口和磁盘设备全部由DPU提供。DPU上运行了云平台的管理、网络和存储相关的组件,管理模块负责裸金属实例生命周期的管理,网络模块负责裸金属虚拟网口的实现和网络流量的转发,存储模块负责裸金属云盘的实现和存储网络协议栈的终结。在DPU场景下,裸金属的发放和管理流程如下: <br> 1. 通过云平台API或UI界面选择裸金属规格,创建裸金属实例; <br> 2. 云平台conductor组件初始化裸金属实例化流程,调用DPU上运行的管理模块,完成裸金属实例的配置; <br> 3. 云平台创建虚拟网口,在DPU上实现虚拟网口后端的初始化,裸金属在启动之后通过标准virtio驱动扫描到网口设备;同时将网口信息同步给SDN控制器,SDN控制器将流表下发到裸金属节点DPU上的vSwitch上,实现裸金属与其他实例的网络互通; <br> 4. 云平台创建云盘设备,通过iSCSI等存储网络协议栈在DPU上对接远端块存储系统,将远端卷设备抽象为标准SPDK bdev块设备,并通过NVMe/virtio-blk等后端提供给裸金属实例作为磁盘设备。|
|
||||
| 技术发展及开源工作建议 |1. 增强云平台管理组件在DPU上的部署和与DPU OS中相关驱动对接方案的研究,以便不同云厂商可以更高效的将相关软件组件部署到不同厂商的DPU上; <br> 2. 探索存储模块中NVMe-oF存储网络协议栈的应用研究,以提供更高性能云盘服务|
|
||||
|
||||
# 5. Next Step
|
||||
|
||||
@ -96,7 +96,7 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
|
||||
**T**he operational service layer is the user-facing service layer. On one hand, it enables the provision of computing force network services to users based on underlying computing and network resources. On the other hand, it collaborates with other computing providers to build a unified transaction service platform, supporting new business models such as "computing force e-commerce."
|
||||
|
||||

|
||||

|
||||
|
||||
(If you would like to learn more about specific technical areas in the graph, you can refer to China Mobile's "Computing Force Network White Paper" and "Computing Force Network Technical White Paper".)
|
||||
|
||||
@ -118,7 +118,7 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| Use Case Description | With the deepening of digital transformation of the whole society and industry, cloud office has become more and more common. Cloud based office has the characteristics of resource on-demand, convenience and high mobility, and is favored by large and medium-sized enterprises. Cloud desktop is a specific implementation method. By centrally managing the office computing resources required by enterprise employees and adopting large-scale and digital methods, IT Capital Expenditure and Operating Expense(CAPEX & OPX) can be reduced, and production efficiency can be improved. Due to the presence of branches throughout the country and even globally, enterprises have requirements for both computing resource and network connectivity. Therefore, this scenario can be considered a typical scenario for computing force network.|
|
||||
| Current Solutions and Gap Analysis | In traditional solutions, cloud desktop allocation is usually based on the geographic location of employees, without considering network status. In this way, it is uncertain whether employees who move to another location will still have the same usage experience as the resident. The overall IT resource utilization rate of the enterprise cannot achieve optimal results.|
|
||||
| Computing Force Network Requirements Derivation | **Virtual Desktop Infrastructure Requirements Based on Computing and Network Convergence:** <br> 1. When users use cloud desktops, they have different requirements for latency and bandwidth based on the purpose of the cloud desktop. For example, cloud desktops for office use generally require a latency of less than 30ms and a bandwidth of around 2M, while for simulation design cloud desktops, the latency is lower and the bandwidth is higher. Therefore, a good solution requires the ability to calculate a network path with appropriate latency and bandwidth based on the cloud desktop type required by the user when selecting a computing resource pool. In this scenario, the computing force network is required to have network scheduling capability. <br> 2. Additionally, the required computing and storage resources may vary depending on the type of cloud desktop. For example, office type cloud desktops generally only require CPU and some memory, while designing simulation type cloud desktops typically requires GPU, as well as more CPU and memory. Therefore, when selecting a computing resource pool, computing force network should be able to select computing entities with the required hardware form and physical capacity based on the type of cloud desktop. Computing force network need to have computing scheduling capabilities. <br> 3. Employees may travel outside their premises at any time. In order to ensure a consistent experience for users using cloud desktops in their new location, computing force network needs to be able to reassign cloud desktop resources based on the new physical location of employees after identifying their movement, and then perform cloud desktop migration.|
|
||||
| Reference Implementation | In this scenario, a VDI management system (hereinafter referred to as VDI Center) and a computing force network brain are required to collaborate. The system architecture diagram is as follows: <br>  <br> Specific workflow: <br> 1. Enterprises deploy cloud desktop server resource pools in different geographical locations. This can be achieved through self built private cloud data centers or by using public cloud services. VDI Center is a centralized cloud desktop management system. The VDI Center reports all computing resource information to the computing force network brain. The computing force network brain simultaneously maintains the information of computing and network. <br> 2. Users bring network SLA requirements and computing resource requirements to the VDI Center to apply for cloud desktop. <br> 3.The VDI Center requests an appropriate resource pool from the computing force network brain with the user's constrained needs. The computing force network brain selects an appropriate cloud resource pool based on the global optimal strategy and calculates the network path from the user access point to the cloud resource pool. Then, the computing force network brain returns the selected resource pool information and pre-establishes the path. <br> 4. After obtaining the optimal resource pool information, the VDI Center applies for virtual desktop through the cloud management platform of that resource pool and returns the information of the cloud desktop to the user. <br> 5. Users access the cloud desktop through the previously established path. <br> 6. User travels to other regions and initiates a cloud desktop migration request. <br> 7. The VDI Center requests a new and suitable resource pool from the computing force network brain again. The computing force network brain recalculates the optimal resource pool, establishes a new path, and returns the results to the VDI Center. <br> 8. VDI Center discovered a better resource pool and initiated virtual machine migration process. <br> 9. Users access a new cloud desktop through a new path.|
|
||||
| Reference Implementation | In this scenario, a VDI management system (hereinafter referred to as VDI Center) and a computing force network brain are required to collaborate. The system architecture diagram is as follows: <br>  <br> Specific workflow: <br> 1. Enterprises deploy cloud desktop server resource pools in different geographical locations. This can be achieved through self built private cloud data centers or by using public cloud services. VDI Center is a centralized cloud desktop management system. The VDI Center reports all computing resource information to the computing force network brain. The computing force network brain simultaneously maintains the information of computing and network. <br> 2. Users bring network SLA requirements and computing resource requirements to the VDI Center to apply for cloud desktop. <br> 3.The VDI Center requests an appropriate resource pool from the computing force network brain with the user's constrained needs. The computing force network brain selects an appropriate cloud resource pool based on the global optimal strategy and calculates the network path from the user access point to the cloud resource pool. Then, the computing force network brain returns the selected resource pool information and pre-establishes the path. <br> 4. After obtaining the optimal resource pool information, the VDI Center applies for virtual desktop through the cloud management platform of that resource pool and returns the information of the cloud desktop to the user. <br> 5. Users access the cloud desktop through the previously established path. <br> 6. User travels to other regions and initiates a cloud desktop migration request. <br> 7. The VDI Center requests a new and suitable resource pool from the computing force network brain again. The computing force network brain recalculates the optimal resource pool, establishes a new path, and returns the results to the VDI Center. <br> 8. VDI Center discovered a better resource pool and initiated virtual machine migration process. <br> 9. Users access a new cloud desktop through a new path.|
|
||||
| Proposal of Technology development and open-source work| It is recommended to conduct further research on the computing force network brain as follows: <br> 1. The computing force network brain has a set of multi-objective optimization scheduling algorithms. Multiple objectives include balancing computing resources, minimizing network latency, and optimizing paths, and so on. <br> 2. The computing force network brain can manage various forms of computing resources (such as CPU, GPU, ASIC, etc.) and establish unified metrics.|
|
||||
|
||||
|
||||
@ -128,7 +128,7 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
|:----|:----|
|
||||
| Contributor | China Mobile Research Institute: Weisen Pan |
|
||||
| Application Name | AI-based Computer Force Network Traffic Control and Computer Force Matching |
|
||||
| Use Case Description | 1. Computer Force Network integrates distributed and ubiquitous computing capabilities in different geographic locations, and its sources include various computing devices such as cloud computing nodes, edge computing nodes, end devices, network devices, etc. The computing tasks in the CFN environment are large in volume and diverse in type, including data analysis, AI reasoning, graphics rendering, and other computing tasks. In this case, the traditional traffic control strategy may not be able to effectively handle the diversity and magnitude of tasks, which may lead to the waste of computing resources, delay of computing tasks, and degradation of service quality. To solve these problems, AI-based traffic control and computing force matching can be used to train AI models using deep learning algorithms by collecting a large amount of network traffic data, device state data, and task demand data. The model can not only learn the pattern of network traffic and computing tasks but also predict future traffic changes and task demands, as well as the computing capacity of devices, and adjust the traffic control strategy and arithmetic matching strategy in real-time based on this information. <br> 2.With the help of AI, operators can manage traffic and computing force more effectively, reduce network congestion, improve the utilization of computing resources, reduce the latency of computing tasks, and improve the quality of service. For example, when a large number of data analysis tasks are predicted to be coming, AI systems can adjust network configurations in advance to prioritize allocating computing resources to these tasks to meet demand. When the capacity of computing devices is predicted to be insufficient to handle the upcoming tasks, the AI system can adjust the traffic control policy in advance to redirect some tasks to other devices to prevent congestion. <br> 3. AI-based Computer Force Network traffic control and computer force matching bring significant performance improvements to large-scale CFN, enabling operators to manage computing resources better to meet the demands of various computing tasks. <br> |
|
||||
| Use Case Description | 1. Computer Force Network integrates distributed and ubiquitous computing capabilities in different geographic locations, and its sources include various computing devices such as cloud computing nodes, edge computing nodes, end devices, network devices, etc. The computing tasks in the CFN environment are large in volume and diverse in type, including data analysis, AI reasoning, graphics rendering, and other computing tasks. In this case, the traditional traffic control strategy may not be able to effectively handle the diversity and magnitude of tasks, which may lead to the waste of computing resources, delay of computing tasks, and degradation of service quality. To solve these problems, AI-based traffic control and computing force matching can be used to train AI models using deep learning algorithms by collecting a large amount of network traffic data, device state data, and task demand data. The model can not only learn the pattern of network traffic and computing tasks but also predict future traffic changes and task demands, as well as the computing capacity of devices, and adjust the traffic control strategy and arithmetic matching strategy in real-time based on this information. <br> 2.With the help of AI, operators can manage traffic and computing force more effectively, reduce network congestion, improve the utilization of computing resources, reduce the latency of computing tasks, and improve the quality of service. For example, when a large number of data analysis tasks are predicted to be coming, AI systems can adjust network configurations in advance to prioritize allocating computing resources to these tasks to meet demand. When the capacity of computing devices is predicted to be insufficient to handle the upcoming tasks, the AI system can adjust the traffic control policy in advance to redirect some tasks to other devices to prevent congestion. <br> 3. AI-based Computer Force Network traffic control and computer force matching bring significant performance improvements to large-scale CFN, enabling operators to manage computing resources better to meet the demands of various computing tasks. <br> |
|
||||
| Current Solutions and Gap Analysis | AI-based Computer Force Network Traffic Control and Computer Force Matching Through artificial intelligence technology, it can monitor the status of CFN in real time, dynamically predict network traffic demand, and automatically optimize CFN resource allocation and load balancing. It can also continuously learn and improve its own traffic control strategy through deep learning algorithms to make it more adaptable to complex and variable network environments. <br> Gap Analysis: <br> 1.Dynamic and adaptive: Traditional traffic control methods tend to be more static and difficult to adapt to the rapid changes in the future CFN environment. AI-based traffic control and computer force matching are highly dynamic and adaptive, and can dynamically adjust traffic control policies and computer force allocation policies based on real-time network status and predicted traffic demand. <br> 2. Learning and improvement: Traditional traffic control methods cannot often learn and improve themselves. On the other hand, AI-based traffic control and computer force matching can continuously learn and improve their own traffic control and computer force matching strategies through deep learning algorithms, making them more adaptable to complex and changing network environments. <br> 3. Adaptability to future technologies: With the rapid development of CFN and related applications, the future CFN environment and traffic demand may be more complex and variable. Therefore, AI-based traffic control and computer force matching are better adaptable and forward-looking for future CFN and related applications.|
|
||||
| Computing Force Network Requirements Derivation | In CFN, traffic control and reasonable matching of computer force are crucial to ensure efficient operation and resource optimization. This requires a system that can adjust the flow control policy and arithmetic matching in real-time and dynamically. Artificial intelligence-based flow control and computer force matching are expected to meet this need. The following is the specific requirement derivation process: <br> 1. Efficient resource utilization: In a large-scale, distributed CFN, the efficiency of resource utilization directly affects the operational efficiency and cost of the entire network. AI technology enables more accurate traffic prediction and scheduling, resulting in more rational and efficient utilization of resources. <br> 2. Dynamic adjustment and optimization: Network traffic and task demand may change with time, applications, and user behavior, which requires traffic control policies to respond to these changes in real-time. AI technology can achieve dynamic adjustment and optimization of traffic control policies through real-time learning and prediction and reasonably match the optimal computing force. <br> 3.Load balancing: In the face of sudden changes in traffic or changes in task demand, it is critical to maintain network load balancing. AI technology can dynamically adjust traffic and task distribution to support load balancing by monitoring and predicting network status in real-time. <br> 4. Quality of Service Assurance: In ensuring the quality of service, AI technology can improve the quality of service by prioritizing essential tasks and services based on the predicted network state and task demands. <br> 5. Automation management: By automatically learning and updating rules, AI technology can reduce the workload of CFN management and achieve a higher degree of automation. <br> Therefore, the introduction of AI-based traffic control and computer force matching can improve the operational efficiency and service quality of CFN and achieve a higher degree of automated management, which is in line with the development needs of CFN.|
|
||||
| Reference Implementation | 1. Data collection: Collect historical data in CFN, such as the computing force utilization of each node, task execution time, network latency, etc., as the data basis for training AI models. <br> 2. Data pre-processing: Pre-process the collected data, including data cleaning, format conversion, feature extraction, etc. <br> 3. Model selection training: According to the characteristics and needs of CFN, suitable AI models (such as deep learning models, reinforcement learning models, etc.) are selected for training. The training goal is for AI models to learn how to perform optimal traffic control and arithmetic power allocation under various conditions. <br> 4. Model testing and optimization: The trained AI models are tested in a simulated or natural environment, and the model is adjusted and optimized according to the test results. <br> 5. Model deployment: The optimized AI model is deployed to CFN for traffic control and arithmetic guidance according to real-time network status and task requirements. <br> 6. Real-time adjustment: The model needs to be dynamically adjusted and optimized according to the real-time network status and task demand data collected after deployment. <br> 7. Model update: The model is regularly updated and optimized according to the network operation and model performance. <br> 8. Continuous monitoring and adjustment: After the model is deployed, the network state and task execution need to be continuously monitored, the AI model needs to be adjusted as required, and the model needs to be periodically retrained to cope with changes in the network environment. |
|
||||
@ -142,9 +142,9 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| Contributor | Inspur - Geng Xiaoqiao |
|
||||
| Application Name |Integrated computing and network scheduling for video applications in rail transit scenario|
|
||||
| Use Case Description | Based on the intelligent video scene of rail transit and focusing on customer business, integrated computing and network scheduling capability is built. Perceiving and analyzing users' requirements on delay and cost, coordinately scheduling and allocating computing and storage resources, as well as realizing dynamic optimization of scheduling policies, so as to provide customers with on-demand, flexible and intelligent computing force network services. At the same time, it is widely adapted to various industry application scenarios, enabling intelligent transformation and innovation of video services. |
|
||||
| Current Solutions and Gap Analysis | 1.Computing and network resources are heterogeneous and ubiquitous, services are complex and performance requirements are high. However, the traditional solutions have synergy barriers between the network, cloud, and service, which cannot meet the scheduling requirements of various scenarios. <br> 2.During peak hours, the data transmission volume is large and the network load is high, leading to high latency and affecting the quality of video service, further putting forward higher requirements and challenges for the optimization of video scheduling solutions. <br>  <br> 3. Video business intelligence is insufficient, and a closed loop of automatic supervision and efficient early warning disposal has not been formed.|
|
||||
| Current Solutions and Gap Analysis | 1.Computing and network resources are heterogeneous and ubiquitous, services are complex and performance requirements are high. However, the traditional solutions have synergy barriers between the network, cloud, and service, which cannot meet the scheduling requirements of various scenarios. <br> 2.During peak hours, the data transmission volume is large and the network load is high, leading to high latency and affecting the quality of video service, further putting forward higher requirements and challenges for the optimization of video scheduling solutions. <br>  <br> 3. Video business intelligence is insufficient, and a closed loop of automatic supervision and efficient early warning disposal has not been formed.|
|
||||
| Computing Force Network Requirements Derivation | 1.Based on the measurement of resource status and business requirements, combining with optimization algorithms, the optimization scheduling and allocation of computing force resources in different time periods and different sites are carried out, to establish a collaborative technology system of computing force network scheduling for industrial applications. <br> 2.For all kinds of video users and business, to provide task-based services (such as optimal path, nearest distance, lowest cost, and etc.), as well as AI intelligent video services. |
|
||||
| Reference Implementation |  <br> 1. Perceiving, collecting, and analyzing underlying computing resources, network resources, and storage resources, as well as perceiving user service types, demands on latency, transmitted data volume, upload traffic, and etc. <br> 2.Based on the user's business requirements of delay and cost, and combining the overall system modeling, business rule analysis, optimization strategy solving and system module docking, to provide intelligent scheduling capabilities including time-sharing tide scheduling, cross-region scheduling, and etc. <br> 3.Evaluating whether the current scheduling policy can meet the service requirements of users in real time, and feeding back relevant indicators to the intelligent scheduling module, then the scheduling policy can be dynamically optimized and adjusted. <br> 4.Relevant processing tasks such as video processing, AI reasoning, data processing, and etc. are flexibly delivered to related computing resources, and providing efficient intelligent video services such as automatic video data backup, AI training, and AI video real-time reasoning, and etc. |
|
||||
| Reference Implementation |  <br> 1. Perceiving, collecting, and analyzing underlying computing resources, network resources, and storage resources, as well as perceiving user service types, demands on latency, transmitted data volume, upload traffic, and etc. <br> 2.Based on the user's business requirements of delay and cost, and combining the overall system modeling, business rule analysis, optimization strategy solving and system module docking, to provide intelligent scheduling capabilities including time-sharing tide scheduling, cross-region scheduling, and etc. <br> 3.Evaluating whether the current scheduling policy can meet the service requirements of users in real time, and feeding back relevant indicators to the intelligent scheduling module, then the scheduling policy can be dynamically optimized and adjusted. <br> 4.Relevant processing tasks such as video processing, AI reasoning, data processing, and etc. are flexibly delivered to related computing resources, and providing efficient intelligent video services such as automatic video data backup, AI training, and AI video real-time reasoning, and etc. |
|
||||
| Proposal of Technology development and open-source work | 1. Combining AI intelligent video capabilities with computing force networks to meet the diversified requirements of industry scenarios. <br> 2. It is suggested to carry out related research on computing and network resources measurement, in order to provide a unified resource template for computing force network.|
|
||||
|
||||
## 4.4 Scheduling of Private Computing Service Based on Computing Force Network
|
||||
@ -155,7 +155,7 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| Use Case Description |When individuals/enterprises apply for loans from banks, banks need to assess lending risks and identify the risks of users borrowing excessively or excessively. By building a privacy computing platform, it is possible to utilizes privacy queries and multi-party joint statistics, and collaborate with multiple banks to jointly calculate the total loan amount of each bank before lending. After receiving the joint statistical results, the bank decides whether to issue loans to users.|
|
||||
| Current Solutions and Gap Analysis | |
|
||||
| Computing Force Network Requirements Derivation | Without solving computing force and communication issues, the large-scale application of privacy computing will be impossible to achieve. Due to massive data needing processing, privacy computing requires super-high bandwidth and large amount of computing force. <br>Besides, privacy computing also put forward higher requirements for computing force network convergent scheduling. Hidden query services and multi-party joint statistical services involve collaborative computing among multiple computing force nodes, data ciphertexts between nodes, and encryption algorithms. It is necessary for computing force networks to have the collaborative scheduling ability of computing force and networks, which can meet network transmission needs, and comprehensively consider transmission delay and task execution delay of computing nodes to eliminate the "barrel effect" caused by computing force shortfalls. At the same time, it is necessary for the computing force network to have dynamic resource scheduling capabilities, which can meet the needs of business scheduling in real-time.|
|
||||
| Reference Implementation |  <br> 1. The bank initiates a joint model training service request; <br> 2. The operation center of the CFN submits a business request to the CFN brain; <br> 3. CFN brain analysis business requests (which may include location, resource requirements, etc.), query available nodes and paths (dedicated/private networks), and reply to the CFN operation center for optional solutions; <br> 4. The CFN operations center responds about resource solution and price information to bank; <br> 5. Bank select and confirm preferred solution and price; <br> 6. The CFN operation center will send the selected solution to the CFN brain; <br> 7. CFN brain conduct self verification to check whether the selected solution can be satisfied (based on digital twin technology or other simulation technologies); <br> 8. CFN brain reply to the self verification status of the solution to CFN operations center (confirmation of information such as computing force, network resources, etc.) ; <br> 9.CFN operations center double confirm the plan; <br> 10. CFN brain initiates resource opening and network establishment requests to the CFN infrastructure layer, and send service instantiation request to CFN infrastructure layer; <br> 11. CFN infrastructure layer reply that computing and network resources as well as services are prepared; <br> 12. CFN brain reply to CFN operation center about service ready information; <br> 13. The CFN operation center responds to bank about service ready info and the bank can start to conducts model training and deployed model inference.|
|
||||
| Reference Implementation | 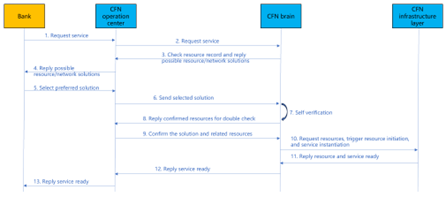 <br> 1. The bank initiates a joint model training service request; <br> 2. The operation center of the CFN submits a business request to the CFN brain; <br> 3. CFN brain analysis business requests (which may include location, resource requirements, etc.), query available nodes and paths (dedicated/private networks), and reply to the CFN operation center for optional solutions; <br> 4. The CFN operations center responds about resource solution and price information to bank; <br> 5. Bank select and confirm preferred solution and price; <br> 6. The CFN operation center will send the selected solution to the CFN brain; <br> 7. CFN brain conduct self verification to check whether the selected solution can be satisfied (based on digital twin technology or other simulation technologies); <br> 8. CFN brain reply to the self verification status of the solution to CFN operations center (confirmation of information such as computing force, network resources, etc.) ; <br> 9.CFN operations center double confirm the plan; <br> 10. CFN brain initiates resource opening and network establishment requests to the CFN infrastructure layer, and send service instantiation request to CFN infrastructure layer; <br> 11. CFN infrastructure layer reply that computing and network resources as well as services are prepared; <br> 12. CFN brain reply to CFN operation center about service ready information; <br> 13. The CFN operation center responds to bank about service ready info and the bank can start to conducts model training and deployed model inference.|
|
||||
| Proposal of Technology development and open-source work | |
|
||||
|
||||
## 4.5 Cross-Architecture deployment and migration of AI Applications in CFN
|
||||
@ -165,9 +165,9 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| Contributor | China Mobile Research Institute – Qihui Zhao |
|
||||
| Application Name | AI applications |
|
||||
| Use Case Description | When users apply for AI services from computing force network, taking facial recognition as an example, they will provide facial recognition task type, data to be processed (such as image transmission interface, image quantity, image size), preferred detection location, processing speed, cost constraints, etc. The computing force network will choose a suitable facial recognition software and a computing force cluster to deploy facial recognition software, complete configuration, and provide services based on user needs. <br> Since the computing force network forms a unified network with computing force of different sources and types, the underlying computing force that used to carries the facial recognition service can be any one or more of Nvidia GPU, Intel CPU, Huawei NPU, Cambrian MLU, Haiguang DCU and many other intelligent chips. Therefore, the deployment, operation, and migration of AI applications on heterogeneous computing chips from multiple vendors is one of the typical use cases of computing force networks. This use case is similar to the AI application’s cross architecture migration scenario in cloud computing. <br> In addition to users applying for AI services from computing force network, the above use case is also suitable for users to deploy self-developed AI applications into computing force network. |
|
||||
| Current Solutions and Gap Analysis | AI applications (i.e., AI services) generally requires the support of "AI framework + Toolchain + Hardware", where: AI framework refers to PaddlePaddle, Pytorch, TensorFlow, etc.; Hardware refers to the AI chips of various device manufacturers; The Toolchain is a series of software built by various AI-chip manufacturers around their AI chips, including but not limited to IDE, compiler, runtime, device driver, etc. At present, users need to choose programming languages and framework models, specify hardware backend, and perform integrated compilation and linking at application development and design stages. If wanting to run AI applications on any AI chips in computing force network, it is necessary to develop multiple versions of codes, complete the compilation for different AI chips, using the development toolchain matched by each chip, and then deploy to the runtime of specific AI chips. The overall development difficulty is high, and the software maintenance cost is high. <br>  |
|
||||
| Computing Force Network Requirements Derivation | 1. To simplify the difficulty of user development and deployment of AI applications, CFN needs to form a software stack that supports cross architecture development and deployment of AI applications in collaboration with AI frameworks, chips, and related toolchain, shield the underlying hardware differences for users. <br>  <br> 2. Computing force networks need to understand user’s descriptive service quality requirements, support transforming the requirements into resource, network, storage and other requirements that can be understood by cloud infrastructure, and support to form multiple resource combination as solutions to meet user SLA requirements. <br> 3. The computing force network needs to measure the underlying heterogeneous chips of different vendors according to unified standards, so that computing force network can calculate different resource combination schemes based on user descriptive SLA requirements. <br> 4. The computing force network needs to monitor the entire state of the system to support resource scheduling, application deployment, etc. |
|
||||
| Reference Implementation | This section is only a solution designed for cross architecture deployment and migration of AI applications, and other implementations and processes may also exist. <br>  <br> Workflows: <br> Pre1. The orchestration and management layer has already managed the underlying computing resource pool and monitored the resource situation within the pool in real-time. <br> Pre2. The computing service provider prepares a cross architecture basic image based on the resource types in the computing resource pool, and registers the image in the central image repository of the orchestration and management layer. A cross architecture runtime is at least included in the cross architecture basic image. This cross architecture runtime can provide a unified abstraction of computing resources for upper level businesses, thereby shielding underlying hardware differences; and can translate unified AI calls into API or instruction call of chips’ toolchain to execute the computing task. <br> 1. Computing force network provides AI application developers (i.e. users) with a flexible and loadable local cross architecture development environment, including cross architecture IDEs (compilers, SDKs, etc.) and cross architecture environment simulators (flexibly adapted according to the user's local underlying hardware type, simulating unified and abstract computing resources for application debugging). <br> 2. After completing AI application development, users can generate cross architecture executable files through the cross architecture development environment, and upload them to the cross architecture business executable file repository of CFN orchestration and management layer. <br> 3. Users propose descriptive SLA requirements for AI application deployment to CFN, and the orchestration and management layer receives SLA requests. <br> 4. The orchestration and management layer analyzes SLA requirements based on monitoring data of multiple types of resources in CFN and converts them into resource requirements that can be understood by the infrastructure layer. This resource requirement can be met by multiple resource combinations, and after the user selects a specific combination scheme, it triggers application deployment. <br> 5. The application deployment process first completes the generation of AI application images and deployment files. For the image, the corresponding cross architecture basic image will be pulled from the central image repository based on the underlying resource type, and automatically packaged with the cross architecture executable file of the AI application to be deployed to generate a complete cross architecture AI application image. The complete AI application image will be distributed to the image repository in the underlying resource pool. For deployment files, automatic deployment files will be generated based on the underlying environment type (bare metal environment, container environment, virtual machine environment), resolved resource requirements, image location, business configuration, and other information/files (which can be scripts, Helm Chart, Heat templates, etc.) <br> 6. The orchestration and management component in the infrastructure layer resource pool deploys AI applications based on deployment files, and complete cross architecture AI application image. <br> 7. If AI application needs to be migrated to resource pools with other chips (CPU, FPGA, ASIC, etc.), repeat steps 4, 5, and 6. |
|
||||
| Current Solutions and Gap Analysis | AI applications (i.e., AI services) generally requires the support of "AI framework + Toolchain + Hardware", where: AI framework refers to PaddlePaddle, Pytorch, TensorFlow, etc.; Hardware refers to the AI chips of various device manufacturers; The Toolchain is a series of software built by various AI-chip manufacturers around their AI chips, including but not limited to IDE, compiler, runtime, device driver, etc. At present, users need to choose programming languages and framework models, specify hardware backend, and perform integrated compilation and linking at application development and design stages. If wanting to run AI applications on any AI chips in computing force network, it is necessary to develop multiple versions of codes, complete the compilation for different AI chips, using the development toolchain matched by each chip, and then deploy to the runtime of specific AI chips. The overall development difficulty is high, and the software maintenance cost is high. <br>  |
|
||||
| Computing Force Network Requirements Derivation | 1. To simplify the difficulty of user development and deployment of AI applications, CFN needs to form a software stack that supports cross architecture development and deployment of AI applications in collaboration with AI frameworks, chips, and related toolchain, shield the underlying hardware differences for users. <br>  <br> 2. Computing force networks need to understand user’s descriptive service quality requirements, support transforming the requirements into resource, network, storage and other requirements that can be understood by cloud infrastructure, and support to form multiple resource combination as solutions to meet user SLA requirements. <br> 3. The computing force network needs to measure the underlying heterogeneous chips of different vendors according to unified standards, so that computing force network can calculate different resource combination schemes based on user descriptive SLA requirements. <br> 4. The computing force network needs to monitor the entire state of the system to support resource scheduling, application deployment, etc. |
|
||||
| Reference Implementation | This section is only a solution designed for cross architecture deployment and migration of AI applications, and other implementations and processes may also exist. <br>  <br> Workflows: <br> Pre1. The orchestration and management layer has already managed the underlying computing resource pool and monitored the resource situation within the pool in real-time. <br> Pre2. The computing service provider prepares a cross architecture basic image based on the resource types in the computing resource pool, and registers the image in the central image repository of the orchestration and management layer. A cross architecture runtime is at least included in the cross architecture basic image. This cross architecture runtime can provide a unified abstraction of computing resources for upper level businesses, thereby shielding underlying hardware differences; and can translate unified AI calls into API or instruction call of chips’ toolchain to execute the computing task. <br> 1. Computing force network provides AI application developers (i.e. users) with a flexible and loadable local cross architecture development environment, including cross architecture IDEs (compilers, SDKs, etc.) and cross architecture environment simulators (flexibly adapted according to the user's local underlying hardware type, simulating unified and abstract computing resources for application debugging). <br> 2. After completing AI application development, users can generate cross architecture executable files through the cross architecture development environment, and upload them to the cross architecture business executable file repository of CFN orchestration and management layer. <br> 3. Users propose descriptive SLA requirements for AI application deployment to CFN, and the orchestration and management layer receives SLA requests. <br> 4. The orchestration and management layer analyzes SLA requirements based on monitoring data of multiple types of resources in CFN and converts them into resource requirements that can be understood by the infrastructure layer. This resource requirement can be met by multiple resource combinations, and after the user selects a specific combination scheme, it triggers application deployment. <br> 5. The application deployment process first completes the generation of AI application images and deployment files. For the image, the corresponding cross architecture basic image will be pulled from the central image repository based on the underlying resource type, and automatically packaged with the cross architecture executable file of the AI application to be deployed to generate a complete cross architecture AI application image. The complete AI application image will be distributed to the image repository in the underlying resource pool. For deployment files, automatic deployment files will be generated based on the underlying environment type (bare metal environment, container environment, virtual machine environment), resolved resource requirements, image location, business configuration, and other information/files (which can be scripts, Helm Chart, Heat templates, etc.) <br> 6. The orchestration and management component in the infrastructure layer resource pool deploys AI applications based on deployment files, and complete cross architecture AI application image. <br> 7. If AI application needs to be migrated to resource pools with other chips (CPU, FPGA, ASIC, etc.), repeat steps 4, 5, and 6. |
|
||||
| Proposal of Technology development and open-source work |1. It is suggested to enhance the research on the migration scheme of cross architecture deployment of AI applications, which can rely on the CFN WG Computing Native sub-working group to explore referenceimplementation. The existing open-source solutions such as Alibaba HALO+ODLA, Intel's DPC++ and LevelZero in the industry can serve as the basis for exploration. <br> 2. It is recommended to conduct research on computing force measurement in order to provide a unified unit for resource computation capability. <br> 3. It is recommended to explore user descriptive SLA requirements and study the ways in which these requirements can be transformed into specific resource requirements. For details, please refer to service models such as PaaS, SaaS, and FaaS. |
|
||||
|
||||
## 4.6 CFN Elastic bare metal
|
||||
@ -176,9 +176,9 @@ Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao
|
||||
| Contributor | China Mobile-Jintao Wang、China Mobile-Qihui Zhao |
|
||||
| Application Name | / |
|
||||
| Use Case Description | According to Section 2.3, the CFN provides a resource-based service model, allowing users to directly apply for resources such as bare metal, virtual machines, and containers to the CFN. Some users are also more inclined to use bare metal services due to considerations such as performance, security, and the difficulty of business virtualization/containerization transformation. Traditional bare metal service resources are difficult to flexibly configure. Customers need to adapt to various drivers. The distribution and management process is lengthy. Whether it is customer experience or management and operation methods, there is a big gap compared with virtualization services. Therefore, how to realize the flexible management and operation and maintenance of various infrastructures by CFN providers, and simplify the use of bare metal by users is an important requirement of the CFN data center. This scenario is also applicable to the fields of cloud computing and cloud-network integration. |
|
||||
| Current Solutions and Gap Analysis | For CFN providers, in the traditional bare metal distribution process, manual configuration of the network is required in the inspection stage, and multiple network switching, node installation, and restart operations are required in the provisioning and tenant stages. The overall process is complicated and lengthy. For users, the number of network cards and storage specifications are fixed, which cannot meet the differentiated network card and storage requirements of different users. In addition, since bare metal NIC drivers and storage clients are visible to users, users need to make adaptations, which further increases the difficulty for users to use bare metal. At the same time, the exposure of the block storage network to the guest operating system also poses security risks. <br> |
|
||||
| Current Solutions and Gap Analysis | For CFN providers, in the traditional bare metal distribution process, manual configuration of the network is required in the inspection stage, and multiple network switching, node installation, and restart operations are required in the provisioning and tenant stages. The overall process is complicated and lengthy. For users, the number of network cards and storage specifications are fixed, which cannot meet the differentiated network card and storage requirements of different users. In addition, since bare metal NIC drivers and storage clients are visible to users, users need to make adaptations, which further increases the difficulty for users to use bare metal. At the same time, the exposure of the block storage network to the guest operating system also poses security risks. <br> |
|
||||
| Computing Force Network Requirements Derivation | The goal is to achieve bare metal provisioning and management as elastic as virtual machines: <br> 1. Bare metal servers are fully automatically provisioned. Through the console self-service application, functions such as automatic image installation, network configuration, and cloud disk mounting can be completed without manual intervention. <br> 2. It is fully compatible with the cloud disk system of the virtualization platform. Bare metal can be started from the cloud disk without operating system installation, which meets the requirements of elastic storage. <br> 3. It is compatible with the virtual machine VPC network and realizes the intercommunication between the bare metal server and the virtual machine network. |
|
||||
| Reference Implementation |  <br> A DPU card needs to be installed on a bare metal server, and the network ports and disk devices of a bare metal instance are all provided by the DPU. The management, network, and storage-related components of the cloud platform run on the DPU. <br> The management module is responsible for the life cycle management of bare metal instances, the network module is responsible for the realization of bare metal virtual network ports and the forwarding of network flows, and the storage module is responsible for the realization of bare metal cloud disks and the termination of the storage protocol stack. <br> In this scenario, the distribution and management process of bare metal is as follows: <br> 1. Select the bare metal flavor through the cloud platform API or UI interface, and create a bare metal instance; <br> 2. The conductor component of the cloud platform initializes the bare metal instantiation process, calls the management module running on the DPU, and completes the configuration of the bare metal instance; <br> 3. The cloud platform creates a virtual network port and initializes the backend of the virtual network port on the DPU. Bare Metal obtains the vNIC through the standard virtio driver after startup. At the same time, the cloud platform synchronizes the network port information to the SDN controller, and the SDN controller sends the flow table to the vSwitch on the DPU of the bare metal node.In this way, the network interworking between bare metal and other instances can be realized; <br> 4. The cloud platform creates a cloud disk, and connects to the remote block storage system on the DPU through a storage protocol stack such as iSCSI. Finally, it is provided to the bare metal instance as a disk through a backend such as NVMe or virtio-blk.|
|
||||
| Reference Implementation |  <br> A DPU card needs to be installed on a bare metal server, and the network ports and disk devices of a bare metal instance are all provided by the DPU. The management, network, and storage-related components of the cloud platform run on the DPU. <br> The management module is responsible for the life cycle management of bare metal instances, the network module is responsible for the realization of bare metal virtual network ports and the forwarding of network flows, and the storage module is responsible for the realization of bare metal cloud disks and the termination of the storage protocol stack. <br> In this scenario, the distribution and management process of bare metal is as follows: <br> 1. Select the bare metal flavor through the cloud platform API or UI interface, and create a bare metal instance; <br> 2. The conductor component of the cloud platform initializes the bare metal instantiation process, calls the management module running on the DPU, and completes the configuration of the bare metal instance; <br> 3. The cloud platform creates a virtual network port and initializes the backend of the virtual network port on the DPU. Bare Metal obtains the vNIC through the standard virtio driver after startup. At the same time, the cloud platform synchronizes the network port information to the SDN controller, and the SDN controller sends the flow table to the vSwitch on the DPU of the bare metal node.In this way, the network interworking between bare metal and other instances can be realized; <br> 4. The cloud platform creates a cloud disk, and connects to the remote block storage system on the DPU through a storage protocol stack such as iSCSI. Finally, it is provided to the bare metal instance as a disk through a backend such as NVMe or virtio-blk.|
|
||||
| Proposal of Technology development and open-source work |1. Research the decoupling scheme of cloud platform components and DPU hardware drivers, so that different cloud vendors can more efficiently deploy cloud platform software components to DPUs of different vendors; <br> 2. Explore the research of NVMe-oF storage network protocol stack to provide high-performance cloud disk services.|
|
||||
|
||||
# 5. Next Step
|
||||
|
||||
Loading…
Reference in New Issue
Block a user