78 KiB
CFN Overview & Use Case Exploration
Versions:
| Version | Date |
|---|---|
| 0.5 | June, 2023 |
| 1.0 | November, 2023 |
Contributors: Jianchao Guo (AsiaInfo), Jian Xu (China Mobile), Jie Nie (China Mobile), Jintao Wang (China Mobile), Lei Huang (China Mobile), Qihui Zhao (China Mobile), Weiguo Hu (99Cloud), Weisen Pan (China Mobile), Xiaoqiao Geng (Inspur), Yong Chen (Nokia), Yongfeng Nie (Huawei), Zhihua Fu (H3C)
1. Introduction
In recent years, driven by multiple factors such as technological innovation and demand orientation, the rapid development speed, wide coverage, and profound impact of the digital economy have become unprecedented. It is becoming a key force in restructuring global resources and reshaping the global economic structure. In the era of digital economy, the total amount of global data and computing force continue to show a high-speed growth trend. In 2021, the total scale of global computing equipment computing force reached 615EFlops, with a growth rate of 44%. Among them, the basic computing force scale was 369EFlops, the intelligent computing force scale was 232EFlops, and the supercomputing force scale was 14EFlops; In 2030, humanity will usher in the era of YB data, with a global computing force scale of 6ZFlops and an average annual growth rate of 65%. Among them, the basic computing force will reach 3.3ZFlops, with an average annual growth rate of 27%; Intelligent computing force reaches 52.5ZFlops, with an average annual growth rate of over 80%; The supercomputing force has reached 0.2ZFlops, with an average annual growth rate of over 34%. At the same time, the rise of new fields such as AI and the metaverse has further promoted the rapid growth of global computing force, driven diversified innovation in computing technology and products, and led to the reconstruction and reshaping of the industrial landscape. As a new productivity in the digital economy era, its importance has been raised to a new height, becoming a solid foundation to support the development of the digital economy, an important engine for global economic development, and playing an important role in promoting scientific and technological progress, industrial digital transformation, and economic and social development.
With the continuous and rapid development of computing force, it is also facing a series of challenges such as diversified applications and imbalanced supply and demand. The ubiquitous network has laid the foundation for the hierarchical distribution of computing force and deep collaboration between computing force. In this context, computing force network has emerged, which interconnect dispersed ubiquitous computing force with ubiquitous global network resources, enabling applications to access computing resources from different regions on demand and in real time. Through the best resource allocation scheme, computing force network can achieve optimal use of resources, and providing computing force services that are easily accessible like "tap water" for thousands of industries. In the future, computing force networks will become a new type of infrastructure in the digital era, just like today's power grids, communication networks, and high-speed rail networks, providing strong impetus for the development of the global digital economy.
This article will interpret the concept of CFN from user perspective, sort out the progress of CFN, analyze use cases and put forward suggestions on how to further promote maturity of CFN.
2. What is computing force network from user perspective
2.1 Concept of computing force network
“Computing force network” has become an industrial hot topic. However, people's understanding of the concept, definition, and scope of computing first networks is not completely unified. But there are also some relatively mainstream and similar definitions:
- In the book "Computing force Era" of China Mobile, it is defined that "computing force network is new type of infrastructure, which is centered around computing, takes network as the foundation, converges network, cloud, data, intelligence, security, edge, terminal, and block chain (ABCDNETS) and provides integrated services. The goal of computing force network is to achieve 'ubiquitous computing force, symbiosis of computing force, intelligent orchestration, and integrated services', gradually promote computing force to become a social level service that can be accessed and used like water and electricity. It vision is achieving easy network access from anywhere, convenient computing force usage at anytime and AI support for anything.” It emphasizes that computing force network is a converge infrastructure supported by “ABCDNTES”.
- In the "Cloud Network Integration 2030 Technology White Paper", China Telecom defined "Computing force network is a technical system that uses the network control plane to transfer computing force and other resource information, based on which to realize information association and high-frequency trading between multi-party and heterogeneous computing, storage, network and other resources. This can meet the diversified needs of emerging businesses' anytime, anywhere, on-demand ', as well as solve the problem of computing force allocation and resource sharing requirements after the scale construction of different types of cloud computing nodes". It points out that computing force network is a technological system which integrates networks with large-scale cloud computing nodes, with the aim of providing flexible computing force allocation and resource sharing.
- China Unicom proposes to implement computing force network centered around the internet. In the "China Unicom Computing Force Network White Paper", it is believed that "the emergence of computing force networks is to improve the collaborative work efficiency of end, edge, and cloud computing." Through computing force network, intelligent machines are ensured to work efficiently and respond quickly to better serve humanity
Comprehensively interpreting the above definition, computing force network is a new type of information infrastructure, and its core basic capabilities are computing force and network. Computing force refers to ubiquitous computing capabilities coming from cloud computing node, edge cloud node, terminal equipment, network equipment, etc., which provides processing capabilities for information and data. Network refers to the high-speed, efficient and reliable network capability including optical access network, optical transmission network, IP network, SDN, deterministic network, etc., which can provide guarantee for the interconnection of users, data and computing force. In addition to basic capabilities, the main characteristics of computing force networks are the deep convergence of computing and networks. Through ubiquitous networks, diverse computing force resources are interconnected. Through centralized control or distributed scheduling methods, computing resources, storage resources, network resources, security resources, etc. are coordinated. In computing force network, the state and location of computing force resources are monitored in real-time; computing tasks and data transmission are coordinated and scheduled uniformly to enable massive applications to access computing resources from different regions on demand and in real-time. It can ensure to provide equally shared, precise matched, location insensitive, and on-demand computing force services to users.
From a technical perspective, computing force network is not an innovation in a certain basic field technology. It is built on existing isolated infrastructure such as computing, storage, network, and security, and achieves Computing as a Service (CaaS) through a series of operations such as resource management, integration, allocation, and re-optimization. It is more about management interaction innovation, business model innovation, and ecological innovation. Just like when the concept of SDN emerged, it was also a management interaction innovation for networks, which was without a revolution in basic network technology. It will evolve from the current resource-based service model of cloud computing, which is simply providing service based on number of CPUs, GPUs, network bandwidth, storage capacity, etc., to a task based interactive service model, which further shielding users from backend computing force and network complexity. Therefore, computing force networks are more about the convergence of computing, network, and multiple technological elements, breaking down the barriers of separation between computing and network, allowing users to focus more on task execution instead of caring about the specific hardware form and physical location of computing force services. Although the name of the computing force network ends with a network, its essence is still centered around computation.
2.2 Capability type of computing force network
This section will first classify computing force from several different dimensions. The analysis of other computing force network capabilities will be gradually updated and improved in the future.
- According to different types of computing force, computing force can be divided into general computing force and specific computing force:
- General computing force: It is composed of CPU chips based on X86 architecture and ARM architecture. It is mainly used to handle basic and diversified computation tasks. It has strong flexibility but high-power consumption. The proportion of general computing force in overall computing force has decreased from 95% in 2016 to 57% in 2020. Although general computing force will still be one of the main types of computing force in the future, its proportion will further decrease.
- Specific computing force:
- Intelligent computing force: This computing force composed of AI chips such as GPU, FPGA, and ASIC, which are mainly used for training and reasoning calculations of artificial intelligence. In terms of technical architecture, the core computing force of artificial intelligence is provided by specialized computing chips, with a focus on diversified computing capabilities such as single precision and semi precision. In terms of application, the artificial intelligence computing center mainly supports the combination of artificial intelligence and traditional industries, improves the production efficiency of traditional industries, and play a significant role in use cases like autonomous driving, auxiliary diagnosis, intelligent manufacturing. The scale of intelligent computing force has grown rapidly in recent years, and its proportion in the overall computing force has increased from 3% in 2016 to 41% in 2020. It is expected that the proportion of intelligent computing force will increase to 70% by the end of this year (2023).
- High performance computing force: This computing force composed of HPCC such as supercomputers. In terms of technical architecture, the core computing force of HPC is provided by high-performance CPUs or coprocessors, which emphasize dual precision universal computing force and pursue precise numerical calculations. In terms of application, HPC Center is mainly used for general and large-scale scientific computing tasks in megaproject or scientific computing fields, such as research in new materials, new energy, new drug design, high-end equipment manufacturing, aerospace vehicle design and other fields. The proportion of supercomputing force in the overall computing force is relatively stable, about 2%.
- According to the location/source of computing force, it can be divided into supercomputing center computing force, intelligent computing center computing force, public cloud computing force, network cloud computing force, private cloud computing force, edge computing force, terminal computing force, etc.:
- Supercomputing center computing force: The computing force provided by supercomputing center, which generally refers to high-performance CPU.
- Intelligent computing center computing force: The computing force provided by intelligent computing center, which generally refers to AI domain chips such as GPU, DSA, FPGA, etc.
- Public cloud computing force: The computing force provided by public cloud data center, which generally includes CPU and GPU.
- Network cloud computing force: The computing force provided by network cloud data centers built by operators after network function virtualization (NFV). This type of computing force is generally dedicated to deploying telecommunications network functions (such as 5GC, IMS, EPC, audio and video network functions, etc.), MANO systems, network management systems, etc. Due to the high security and reliability requirements of network clouds, they are not open to public access. How to use network clouds to provide computing force for computing force network still needs exploration.
- Private cloud computing force: The computing force provided by the internal data center of the enterprise. This kind of computing force is mostly used to deploy enterprise specific software, such as enterprise OA system, industrial management system, development environment, etc. Whether private cloud can be used to provide computing force for computing force network needs to be determined flexibly according to enterprise security requirements. There may be many situations, such as unable to provide computing force, and providing computing force under special security isolation requirements.
- Edge computing force: Edge computing force is a supplement to relatively concentrated cloud computing force such as public clouds and network clouds. Each of edge node has little computing force. But the number of edge nodes is large, and the computing force are widely distributed which can be get from gateways, routers, switches, edge clouds, edge computing servers, etc. In addition, edge computing force types vary greatly, and can be composed of CPU, GPU, FPGA and other heterogeneous computing chips. Edge computing force can support applications deployed at the edge to complete computing tasks, including but not limited to artificial intelligence reasoning applications, video processing, etc. Integrating edge computing force into computing force networks faces challenges in flexible scheduling, efficient management, and stable support.
- Terminal computing force: The computing force provided by personal devices such as PCs, mobile phones, VR devices, etc. It has smaller computing force, more dispersed location distribution, and more quantity. Using such computing force is also a challenge.
Currently, due to various factors such as technology and security, computing force networks will prioritize the collaboration of computing force sourced from supercomputing centers, intelligent computing centers, public clouds, and edge clouds, while other computing force can gradually be involved.
2.3 Service pattern of computing force network
As mentioned in section 2.1, computing force networks provide users with computing as a service (CaaS), and their service modes are divided into the following categories:
- Resource-based service mode
Resource-based service mode of computing force network is like public clouds’ IaaS, which directly provide resources such as cloud hosts, cloud hard drives, and cloud networks. Its characteristic is that computing force network control system only needs to allocate and provide resources but does not need to care about how users use computing force. Users often need to complete resource application and activation of such services through portal or console. Unlike public clouds, computing force network may interface with different forms of cloud or edge computing force from different vendors. In addition, such resource-based service mode requires stable WAN access to ensure quality of network and computing force provided to users. Of course, users may also access it through the public internet, which depends on their needs.
- Platform-based service mode
The computing force network platform-based service mode is an indirect computing force service mode like PaaS. The computing force network system helps users deploy their user-developed applications, run user applications, and monitor the operation process of the applications. At the same time, it can also provide application access, scaling, and other functions. Such service mode still relies on the scheduling, orchestration, deployment of underlay computing force infrastructure. Users also need to pay attention to their business logic.
- Software-based service mode
Similar to the SaaS provided by public cloud, the software-based service mode of Compute Power Network generally means that users choose a specific application software through the service provider platform. Compute Power Network deploys application for users, and users can access application through APIs, without paying attention to the details of the system, software, deployment location, etc.
- Task-based service mode
Task-based service mode, which can also be represented as Task as a Service, is the most intelligent and ideal service mode for computing force network. Users only need to provide descriptive explanations of the tasks to computing force network (such as "deploying a video surveillance business near school A"). The computing force network service provider can understand user needs (such as business type, service quality, reliability, security, cost, etc.), select computing centers independently and flexibly, and select suitable software/application for described scenarios. After deploying and configuring the software/application, the resources and business information of software/application instances will be registered to computing force network control platform, and the instances status will be monitored and updated regularly. Computing force network needs to perceive the location and status of software/application instances, generate routing strategies for accessing these instances, and distribute the strategies to routing nodes in the network. After receiving the message to access the software/application instances, the routing node forwards it according to the issued routing strategies. These strategies often require a comprehensive consideration of computing force state and network state to make the optimized decision. The perception and routing strategy generation for software/application can also be completed by network nodes themselves.
2.4 Computing force network VS Integrated cloud and network
Both "Computing Force Network" and "Cloud-Network Convergence" are based on the core capabilities of computing and networking, they are often compared together and even referred to as equivalent concepts. This section analyzes the differences between the two.
Computing Force Network can be seen as a deepening and upgraded version of Cloud-Network Convergence, and Cloud-Network Convergence is the initial stage of the Computing Force Network. Cloud-Network Convergence can be considered as a subset of the Computing Force Network in terms of its connotation, stage, and scope of influence. The detailed differences can be observed from the following:
- Difference 1: Both Computing Force Network and Cloud-Network Convergence revolve around computing ability, but they have different sources of computing. In Computing Force Network, the sources of computing are more diverse, and the providers of computing force are no longer limited to a few proprietary data centers or clusters. Ideally, computing force can come from any device with computational capabilities, including but not limited to cloud data centers, network devices, end devices, super-computing centers, intelligent computing centers, etc. The ubiquitous computing force is connected through networked approach, such as cloud-edge-terminal collaboration pattern, to achieve efficient sharing of computing force. In contrast, in Cloud-Network Convergence, computing force mainly comes from cloud data centers.
- Difference 2: Both Cloud-Network Convergence and Computing Force Network rely on networks as the foundation, but the way they collaborate with computing force is different. Cloud-Network Convergence has a relatively straightforward interface between computing force and the network, a simple gateway could be enough to connect the computing resources to the network. However, in the case of Computing Force Network, the interactions between computing force and the network can be happened in multiple times in multiple location. The collaboration between the two is achieved not just solely through separate network management components and computing force management components. From the perspective of computing force service providers, a structured characteristic is expected in the Computing Force Network. Taking application-oriented services as an example, the process can be outlined as follows: a) Users submit application requirements to the Computing Force Network, including SLA (Service Level Agreement), reliability, and security needs. b) The Computing Force Network is responsible for translating these descriptive requirements into explicit structured demands. Correspondently, high-quality SLA needs a specific structure composed of ubiquitous computing force combined with deterministic networking. High reliability may require specific redundant structures with location relevance. High security might require virtual network isolation and other structures. c) Finally, the Computing Force Network should perform resource discovery, orchestration, and scheduling based on the structured and complete demands.
- Difference 3: Computing force and network boundaries differ between the two concepts. In the Computing Force Network, computing force gradually moves beyond the traditionally closed boundaries of the cloud, and tightly integrates with the network. From an end-to-end network perspective that connects the cloud and the network, computing force is present within the network itself. Additionally, a small amount of computing force within network devices can also be utilized for data processing purposes.
- Difference 4: The operational service models are different. In Cloud-Network Convergence, computing and network resources are typically treated as independent for resource optimization, scheduling, and provided to external users. While, in the Computing Force Network, computing and network resources are considered as a unified an integrated resource for optimization and scheduling. This approach will better meet complex business requirements such as service quality, reliability, and security. Additionally, the Computing Force Network promotes the development of new application service models and architectures to better adapt to the distributed and ubiquitous nature of its computing and network resources.
3. Related study area of computing force network
In the "Computing Force Network White Paper" by China Mobile, the computing force network system is divided into three layers: the operational service layer, the orchestration and management layer, and the computing and network infrastructure layer.
The computing and network infrastructure layer primarily provides ubiquitous computing infrastructure to meet the computing requirements at central, edge, and on-site levels. It also provides efficient network infrastructure to support flexible user access to ubiquitous computing through the network.
The orchestration and management layer serves as the scheduling center of the computing force network, with the "computing force network brain" at its core. It achieves unified management, orchestration, intelligent scheduling, and global optimization of computing and network resources. It also provides interfaces for computing and network scheduling capabilities to support diverse services in the computing force network.
The operational service layer is the user-facing service layer. On one hand, it enables the provision of computing force network services to users based on underlying computing and network resources. On the other hand, it collaborates with other computing providers to build a unified transaction service platform, supporting new business models such as "computing force e-commerce."

(If you would like to learn more about specific technical areas in the graph, you can refer to China Mobile's "Computing Force Network White Paper" and "Computing Force Network Technical White Paper".)
The above diagram is the Computing Force Network Technology Topology proposed by China Mobile. It lists various technological research areas and classifies them into different layers. In the computing and network infrastructure layer, the technology areas related to computing infrastructure and network infrastructure do not significantly differ from the related technological areas in cloud computing and network development. This indicates that Computing Force Network is not an entirely new technical field in terms of underlying infrastructure technologies but rather an evolution based on existing technology domains.
Furthermore, the integration of computing and networking in the computing and network infrastructure layer is crucial for Computing Force Network, and also the core guarantee for achieving task-oriented interactive service models. This aspect can be further innovated based on the Computing Force Network.
The Orchestration and Management layer and the Operational Service layer depicted in the diagram will give rise to a significant amount of innovation in terms of business models, service models, and management models. These innovations represent the future competitiveness of Computing Force Network service providers in the commercial arena.
This article does not currently address the overall software architecture, technology selection, or implementation process of the specific technical areas depicted in the diagram. The discussion on these topics will be carried out in multiple sub-working groups within CFN WG in the future.
4. Use Cases
4.1 Virtual Desktop Infrastructure Based on Computing and Network Convergence
Use Case Name |
Virtual Desktop Infrastructure Based on Computing and Network Convergence |
|---|---|
| Contributor | Zhihua Fu - New H3C Technologies Co., Ltd. |
| Application Name | Virtual Desktop Infrastructure |
| Use Case Description | With the deepening of digital transformation of the whole society and industry, cloud office has become more and more common. Cloud based office has the characteristics of resource on-demand, convenience and high mobility, and is favored by large and medium-sized enterprises. Cloud desktop is a specific implementation method. By centrally managing the office computing resources required by enterprise employees and adopting large-scale and digital methods, IT Capital Expenditure and Operating Expense(CAPEX & OPX) can be reduced, and production efficiency can be improved. Due to the presence of branches throughout the country and even globally, enterprises have requirements for both computing resource and network connectivity. Therefore, this scenario can be considered a typical scenario for computing force network. |
| Current Solutions and Gap Analysis | In traditional solutions, cloud desktop allocation is usually based on the geographic location of employees, without considering network status. In this way, it is uncertain whether employees who move to another location will still have the same usage experience as the resident. The overall IT resource utilization rate of the enterprise cannot achieve optimal results. |
| Computing Force Network Requirements Derivation | Virtual Desktop Infrastructure Requirements Based on Computing and Network Convergence: 1. When users use cloud desktops, they have different requirements for latency and bandwidth based on the purpose of the cloud desktop. For example, cloud desktops for office use generally require a latency of less than 30ms and a bandwidth of around 2M, while for simulation design cloud desktops, the latency is lower and the bandwidth is higher. Therefore, a good solution requires the ability to calculate a network path with appropriate latency and bandwidth based on the cloud desktop type required by the user when selecting a computing resource pool. In this scenario, the computing force network is required to have network scheduling capability. 2. Additionally, the required computing and storage resources may vary depending on the type of cloud desktop. For example, office type cloud desktops generally only require CPU and some memory, while designing simulation type cloud desktops typically requires GPU, as well as more CPU and memory. Therefore, when selecting a computing resource pool, computing force network should be able to select computing entities with the required hardware form and physical capacity based on the type of cloud desktop. Computing force network need to have computing scheduling capabilities. 3. Employees may travel outside their premises at any time. In order to ensure a consistent experience for users using cloud desktops in their new location, computing force network needs to be able to reassign cloud desktop resources based on the new physical location of employees after identifying their movement, and then perform cloud desktop migration. |
| Reference Implementation | In this scenario, a VDI management system (hereinafter referred to as VDI Center) and a computing force network brain are required to collaborate. The system architecture diagram is as follows:  Specific workflow: 1. Enterprises deploy cloud desktop server resource pools in different geographical locations. This can be achieved through self built private cloud data centers or by using public cloud services. VDI Center is a centralized cloud desktop management system. The VDI Center reports all computing resource information to the computing force network brain. The computing force network brain simultaneously maintains the information of computing and network. 2. Users bring network SLA requirements and computing resource requirements to the VDI Center to apply for cloud desktop. 3.The VDI Center requests an appropriate resource pool from the computing force network brain with the user's constrained needs. The computing force network brain selects an appropriate cloud resource pool based on the global optimal strategy and calculates the network path from the user access point to the cloud resource pool. Then, the computing force network brain returns the selected resource pool information and pre-establishes the path. 4. After obtaining the optimal resource pool information, the VDI Center applies for virtual desktop through the cloud management platform of that resource pool and returns the information of the cloud desktop to the user. 5. Users access the cloud desktop through the previously established path. 6. User travels to other regions and initiates a cloud desktop migration request. 7. The VDI Center requests a new and suitable resource pool from the computing force network brain again. The computing force network brain recalculates the optimal resource pool, establishes a new path, and returns the results to the VDI Center. 8. VDI Center discovered a better resource pool and initiated virtual machine migration process. 9. Users access a new cloud desktop through a new path. |
| Proposal of Technology development and open-source work | It is recommended to conduct further research on the computing force network brain as follows: 1. The computing force network brain has a set of multi-objective optimization scheduling algorithms. Multiple objectives include balancing computing resources, minimizing network latency, and optimizing paths, and so on. 2. The computing force network brain can manage various forms of computing resources (such as CPU, GPU, ASIC, etc.) and establish unified metrics. |
4.2 AI-based Computer Force Network Traffic Control and Computer Force Matching
Use Case Name |
AI-based Computer Force Network Traffic Control and Computer Force Matching |
|---|---|
| Contributor | China Mobile Research Institute: Weisen Pan |
| Application Name | AI-based Computer Force Network Traffic Control and Computer Force Matching |
| Use Case Description | 1. Computer Force Network integrates distributed and ubiquitous computing capabilities in different geographic locations, and its sources include various computing devices such as cloud computing nodes, edge computing nodes, end devices, network devices, etc. The computing tasks in the CFN environment are large in volume and diverse in type, including data analysis, AI reasoning, graphics rendering, and other computing tasks. In this case, the traditional traffic control strategy may not be able to effectively handle the diversity and magnitude of tasks, which may lead to the waste of computing resources, delay of computing tasks, and degradation of service quality. To solve these problems, AI-based traffic control and computing force matching can be used to train AI models using deep learning algorithms by collecting a large amount of network traffic data, device state data, and task demand data. The model can not only learn the pattern of network traffic and computing tasks but also predict future traffic changes and task demands, as well as the computing capacity of devices, and adjust the traffic control strategy and arithmetic matching strategy in real-time based on this information. 2.With the help of AI, operators can manage traffic and computing force more effectively, reduce network congestion, improve the utilization of computing resources, reduce the latency of computing tasks, and improve the quality of service. For example, when a large number of data analysis tasks are predicted to be coming, AI systems can adjust network configurations in advance to prioritize allocating computing resources to these tasks to meet demand. When the capacity of computing devices is predicted to be insufficient to handle the upcoming tasks, the AI system can adjust the traffic control policy in advance to redirect some tasks to other devices to prevent congestion. 3. AI-based Computer Force Network traffic control and computer force matching bring significant performance improvements to large-scale CFN, enabling operators to manage computing resources better to meet the demands of various computing tasks.  |
| Current Solutions and Gap Analysis | AI-based Computer Force Network Traffic Control and Computer Force Matching Through artificial intelligence technology, it can monitor the status of CFN in real time, dynamically predict network traffic demand, and automatically optimize CFN resource allocation and load balancing. It can also continuously learn and improve its own traffic control strategy through deep learning algorithms to make it more adaptable to complex and variable network environments. Gap Analysis: 1.Dynamic and adaptive: Traditional traffic control methods tend to be more static and difficult to adapt to the rapid changes in the future CFN environment. AI-based traffic control and computer force matching are highly dynamic and adaptive, and can dynamically adjust traffic control policies and computer force allocation policies based on real-time network status and predicted traffic demand. 2. Learning and improvement: Traditional traffic control methods cannot often learn and improve themselves. On the other hand, AI-based traffic control and computer force matching can continuously learn and improve their own traffic control and computer force matching strategies through deep learning algorithms, making them more adaptable to complex and changing network environments. 3. Adaptability to future technologies: With the rapid development of CFN and related applications, the future CFN environment and traffic demand may be more complex and variable. Therefore, AI-based traffic control and computer force matching are better adaptable and forward-looking for future CFN and related applications. |
| Computing Force Network Requirements Derivation | In CFN, traffic control and reasonable matching of computer force are crucial to ensure efficient operation and resource optimization. This requires a system that can adjust the flow control policy and arithmetic matching in real-time and dynamically. Artificial intelligence-based flow control and computer force matching are expected to meet this need. The following is the specific requirement derivation process: 1. Efficient resource utilization: In a large-scale, distributed CFN, the efficiency of resource utilization directly affects the operational efficiency and cost of the entire network. AI technology enables more accurate traffic prediction and scheduling, resulting in more rational and efficient utilization of resources. 2. Dynamic adjustment and optimization: Network traffic and task demand may change with time, applications, and user behavior, which requires traffic control policies to respond to these changes in real-time. AI technology can achieve dynamic adjustment and optimization of traffic control policies through real-time learning and prediction and reasonably match the optimal computing force. 3.Load balancing: In the face of sudden changes in traffic or changes in task demand, it is critical to maintain network load balancing. AI technology can dynamically adjust traffic and task distribution to support load balancing by monitoring and predicting network status in real-time. 4. Quality of Service Assurance: In ensuring the quality of service, AI technology can improve the quality of service by prioritizing essential tasks and services based on the predicted network state and task demands. 5. Automation management: By automatically learning and updating rules, AI technology can reduce the workload of CFN management and achieve a higher degree of automation. Therefore, the introduction of AI-based traffic control and computer force matching can improve the operational efficiency and service quality of CFN and achieve a higher degree of automated management, which is in line with the development needs of CFN. |
| Reference Implementation | 1. Data collection: Collect historical data in CFN, such as the computing force utilization of each node, task execution time, network latency, etc., as the data basis for training AI models. 2. Data pre-processing: Pre-process the collected data, including data cleaning, format conversion, feature extraction, etc. 3. Model selection training: According to the characteristics and needs of CFN, suitable AI models (such as deep learning models, reinforcement learning models, etc.) are selected for training. The training goal is for AI models to learn how to perform optimal traffic control and arithmetic power allocation under various conditions. 4. Model testing and optimization: The trained AI models are tested in a simulated or natural environment, and the model is adjusted and optimized according to the test results. 5. Model deployment: The optimized AI model is deployed to CFN for traffic control and arithmetic guidance according to real-time network status and task requirements. 6. Real-time adjustment: The model needs to be dynamically adjusted and optimized according to the real-time network status and task demand data collected after deployment. 7. Model update: The model is regularly updated and optimized according to the network operation and model performance. 8. Continuous monitoring and adjustment: After the model is deployed, the network state and task execution need to be continuously monitored, the AI model needs to be adjusted as required, and the model needs to be periodically retrained to cope with changes in the network environment. |
| Proposal of Technology development and open-source work | 1. In terms of technology development, one is to consider integrating multiple AI models: different AI models may work better in handling different types of tasks or coping with varying states of the network, and one can consider integrating various AI models to optimize the overall performance through integrated learning methods; the second is the development of adaptive algorithms: as the network environment changes, the parameters of AI models need to be adjusted in real-time to cope with these changes. This requires the development of more intelligent and adaptive algorithms that can optimize themselves without human intervention. 2. Regarding open-source work: First, historical data from arithmetic networks should be made public and shared so that more researchers can train and test models based on these data. It is also possible to share already trained AI models for others to use and optimize. Second, to establish standards and specifications: To ensure the synergy and interoperability of different open-source projects, a common set of standards and specifications needs to be established, including but not limited to data formats, API design, methods for model training and testing, etc. |
4.3 Computing Force Network scheduling for video service scenario
Use Case Name |
Computing Force Network scheduling for video service scenario |
|---|---|
| Contributor | Inspur - Geng Xiaoqiao |
| Application Name | Integrated computing and network scheduling for video applications in rail transit scenario |
| Use Case Description | Based on the intelligent video scene of rail transit and focusing on customer business, integrated computing and network scheduling capability is built. Perceiving and analyzing users' requirements on delay and cost, coordinately scheduling and allocating computing and storage resources, as well as realizing dynamic optimization of scheduling policies, so as to provide customers with on-demand, flexible and intelligent computing force network services. At the same time, it is widely adapted to various industry application scenarios, enabling intelligent transformation and innovation of video services. |
| Current Solutions and Gap Analysis | 1.Computing and network resources are heterogeneous and ubiquitous, services are complex and performance requirements are high. However, the traditional solutions have synergy barriers between the network, cloud, and service, which cannot meet the scheduling requirements of various scenarios. 2.During peak hours, the data transmission volume is large and the network load is high, leading to high latency and affecting the quality of video service, further putting forward higher requirements and challenges for the optimization of video scheduling solutions.  3. Video business intelligence is insufficient, and a closed loop of automatic supervision and efficient early warning disposal has not been formed. |
| Computing Force Network Requirements Derivation | 1.Based on the measurement of resource status and business requirements, combining with optimization algorithms, the optimization scheduling and allocation of computing force resources in different time periods and different sites are carried out, to establish a collaborative technology system of computing force network scheduling for industrial applications. 2.For all kinds of video users and business, to provide task-based services (such as optimal path, nearest distance, lowest cost, and etc.), as well as AI intelligent video services. |
| Reference Implementation |  1. Perceiving, collecting, and analyzing underlying computing resources, network resources, and storage resources, as well as perceiving user service types, demands on latency, transmitted data volume, upload traffic, and etc. 2.Based on the user's business requirements of delay and cost, and combining the overall system modeling, business rule analysis, optimization strategy solving and system module docking, to provide intelligent scheduling capabilities including time-sharing tide scheduling, cross-region scheduling, and etc. 3.Evaluating whether the current scheduling policy can meet the service requirements of users in real time, and feeding back relevant indicators to the intelligent scheduling module, then the scheduling policy can be dynamically optimized and adjusted. 4.Relevant processing tasks such as video processing, AI reasoning, data processing, and etc. are flexibly delivered to related computing resources, and providing efficient intelligent video services such as automatic video data backup, AI training, and AI video real-time reasoning, and etc. |
| Proposal of Technology development and open-source work | 1. Combining AI intelligent video capabilities with computing force networks to meet the diversified requirements of industry scenarios. 2. It is suggested to carry out related research on computing and network resources measurement, in order to provide a unified resource template for computing force network. |
4.4 Scheduling of Private Computing Service Based on Computing Force Network
Use Case Name |
Scheduling of Private Computing Service Based on Computing Force Network |
|---|---|
| Contributor | Asia Info-Guo Jianchao |
| Application Name | Private Computing |
| Use Case Description | When individuals/enterprises apply for loans from banks, banks need to assess lending risks and identify the risks of users borrowing excessively or excessively. By building a privacy computing platform, it is possible to utilizes privacy queries and multi-party joint statistics, and collaborate with multiple banks to jointly calculate the total loan amount of each bank before lending. After receiving the joint statistical results, the bank decides whether to issue loans to users. |
| Current Solutions and Gap Analysis | |
| Computing Force Network Requirements Derivation | Without solving computing force and communication issues, the large-scale application of privacy computing will be impossible to achieve. Due to massive data needing processing, privacy computing requires super-high bandwidth and large amount of computing force. Besides, privacy computing also put forward higher requirements for computing force network convergent scheduling. Hidden query services and multi-party joint statistical services involve collaborative computing among multiple computing force nodes, data ciphertexts between nodes, and encryption algorithms. It is necessary for computing force networks to have the collaborative scheduling ability of computing force and networks, which can meet network transmission needs, and comprehensively consider transmission delay and task execution delay of computing nodes to eliminate the "barrel effect" caused by computing force shortfalls. At the same time, it is necessary for the computing force network to have dynamic resource scheduling capabilities, which can meet the needs of business scheduling in real-time. |
| Reference Implementation | 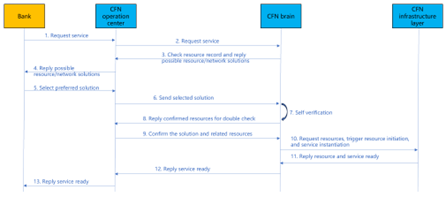 1. The bank initiates a joint model training service request; 2. The operation center of the CFN submits a business request to the CFN brain; 3. CFN brain analysis business requests (which may include location, resource requirements, etc.), query available nodes and paths (dedicated/private networks), and reply to the CFN operation center for optional solutions; 4. The CFN operations center responds about resource solution and price information to bank; 5. Bank select and confirm preferred solution and price; 6. The CFN operation center will send the selected solution to the CFN brain; 7. CFN brain conduct self verification to check whether the selected solution can be satisfied (based on digital twin technology or other simulation technologies); 8. CFN brain reply to the self verification status of the solution to CFN operations center (confirmation of information such as computing force, network resources, etc.) ; 9.CFN operations center double confirm the plan; 10. CFN brain initiates resource opening and network establishment requests to the CFN infrastructure layer, and send service instantiation request to CFN infrastructure layer; 11. CFN infrastructure layer reply that computing and network resources as well as services are prepared; 12. CFN brain reply to CFN operation center about service ready information; 13. The CFN operation center responds to bank about service ready info and the bank can start to conducts model training and deployed model inference. |
| Proposal of Technology development and open-source work |
4.5 Cross-Architecture deployment and migration of AI Applications in CFN
Use Case Name |
Cross-Architecture deployment and migration of AI Applications in CFN |
|---|---|
| Contributor | China Mobile Research Institute – Qihui Zhao |
| Application Name | AI applications |
| Use Case Description | When users apply for AI services from computing force network, taking facial recognition as an example, they will provide facial recognition task type, data to be processed (such as image transmission interface, image quantity, image size), preferred detection location, processing speed, cost constraints, etc. The computing force network will choose a suitable facial recognition software and a computing force cluster to deploy facial recognition software, complete configuration, and provide services based on user needs. Since the computing force network forms a unified network with computing force of different sources and types, the underlying computing force that used to carries the facial recognition service can be any one or more of Nvidia GPU, Intel CPU, Huawei NPU, Cambrian MLU, Haiguang DCU and many other intelligent chips. Therefore, the deployment, operation, and migration of AI applications on heterogeneous computing chips from multiple vendors is one of the typical use cases of computing force networks. This use case is similar to the AI application’s cross architecture migration scenario in cloud computing. In addition to users applying for AI services from computing force network, the above use case is also suitable for users to deploy self-developed AI applications into computing force network. |
| Current Solutions and Gap Analysis | AI applications (i.e., AI services) generally requires the support of "AI framework + Toolchain + Hardware", where: AI framework refers to PaddlePaddle, Pytorch, TensorFlow, etc.; Hardware refers to the AI chips of various device manufacturers; The Toolchain is a series of software built by various AI-chip manufacturers around their AI chips, including but not limited to IDE, compiler, runtime, device driver, etc. At present, users need to choose programming languages and framework models, specify hardware backend, and perform integrated compilation and linking at application development and design stages. If wanting to run AI applications on any AI chips in computing force network, it is necessary to develop multiple versions of codes, complete the compilation for different AI chips, using the development toolchain matched by each chip, and then deploy to the runtime of specific AI chips. The overall development difficulty is high, and the software maintenance cost is high.  |
| Computing Force Network Requirements Derivation | 1. To simplify the difficulty of user development and deployment of AI applications, CFN needs to form a software stack that supports cross architecture development and deployment of AI applications in collaboration with AI frameworks, chips, and related toolchain, shield the underlying hardware differences for users.  2. Computing force networks need to understand user’s descriptive service quality requirements, support transforming the requirements into resource, network, storage and other requirements that can be understood by cloud infrastructure, and support to form multiple resource combination as solutions to meet user SLA requirements. 3. The computing force network needs to measure the underlying heterogeneous chips of different vendors according to unified standards, so that computing force network can calculate different resource combination schemes based on user descriptive SLA requirements. 4. The computing force network needs to monitor the entire state of the system to support resource scheduling, application deployment, etc. |
| Reference Implementation | This section is only a solution designed for cross architecture deployment and migration of AI applications, and other implementations and processes may also exist.  Workflows: Pre1. The orchestration and management layer has already managed the underlying computing resource pool and monitored the resource situation within the pool in real-time. Pre2. The computing service provider prepares a cross architecture basic image based on the resource types in the computing resource pool, and registers the image in the central image repository of the orchestration and management layer. A cross architecture runtime is at least included in the cross architecture basic image. This cross architecture runtime can provide a unified abstraction of computing resources for upper level businesses, thereby shielding underlying hardware differences; and can translate unified AI calls into API or instruction call of chips’ toolchain to execute the computing task. 1. Computing force network provides AI application developers (i.e. users) with a flexible and loadable local cross architecture development environment, including cross architecture IDEs (compilers, SDKs, etc.) and cross architecture environment simulators (flexibly adapted according to the user's local underlying hardware type, simulating unified and abstract computing resources for application debugging). 2. After completing AI application development, users can generate cross architecture executable files through the cross architecture development environment, and upload them to the cross architecture business executable file repository of CFN orchestration and management layer. 3. Users propose descriptive SLA requirements for AI application deployment to CFN, and the orchestration and management layer receives SLA requests. 4. The orchestration and management layer analyzes SLA requirements based on monitoring data of multiple types of resources in CFN and converts them into resource requirements that can be understood by the infrastructure layer. This resource requirement can be met by multiple resource combinations, and after the user selects a specific combination scheme, it triggers application deployment. 5. The application deployment process first completes the generation of AI application images and deployment files. For the image, the corresponding cross architecture basic image will be pulled from the central image repository based on the underlying resource type, and automatically packaged with the cross architecture executable file of the AI application to be deployed to generate a complete cross architecture AI application image. The complete AI application image will be distributed to the image repository in the underlying resource pool. For deployment files, automatic deployment files will be generated based on the underlying environment type (bare metal environment, container environment, virtual machine environment), resolved resource requirements, image location, business configuration, and other information/files (which can be scripts, Helm Chart, Heat templates, etc.) 6. The orchestration and management component in the infrastructure layer resource pool deploys AI applications based on deployment files, and complete cross architecture AI application image. 7. If AI application needs to be migrated to resource pools with other chips (CPU, FPGA, ASIC, etc.), repeat steps 4, 5, and 6. |
| Proposal of Technology development and open-source work | 1. It is suggested to enhance the research on the migration scheme of cross architecture deployment of AI applications, which can rely on the CFN WG Computing Native sub-working group to explore referenceimplementation. The existing open-source solutions such as Alibaba HALO+ODLA, Intel's DPC++ and LevelZero in the industry can serve as the basis for exploration. 2. It is recommended to conduct research on computing force measurement in order to provide a unified unit for resource computation capability. 3. It is recommended to explore user descriptive SLA requirements and study the ways in which these requirements can be transformed into specific resource requirements. For details, please refer to service models such as PaaS, SaaS, and FaaS. |
4.6 CFN Elastic bare metal
Use Case Name |
CFN Elastic bare metal |
|---|---|
| Contributor | China Mobile-Jintao Wang、China Mobile-Qihui Zhao |
| Application Name | / |
| Use Case Description | According to Section 2.3, the CFN provides a resource-based service model, allowing users to directly apply for resources such as bare metal, virtual machines, and containers to the CFN. Some users are also more inclined to use bare metal services due to considerations such as performance, security, and the difficulty of business virtualization/containerization transformation. Traditional bare metal service resources are difficult to flexibly configure. Customers need to adapt to various drivers. The distribution and management process is lengthy. Whether it is customer experience or management and operation methods, there is a big gap compared with virtualization services. Therefore, how to realize the flexible management and operation and maintenance of various infrastructures by CFN providers, and simplify the use of bare metal by users is an important requirement of the CFN data center. This scenario is also applicable to the fields of cloud computing and cloud-network integration. |
| Current Solutions and Gap Analysis | For CFN providers, in the traditional bare metal distribution process, manual configuration of the network is required in the inspection stage, and multiple network switching, node installation, and restart operations are required in the provisioning and tenant stages. The overall process is complicated and lengthy. For users, the number of network cards and storage specifications are fixed, which cannot meet the differentiated network card and storage requirements of different users. In addition, since bare metal NIC drivers and storage clients are visible to users, users need to make adaptations, which further increases the difficulty for users to use bare metal. At the same time, the exposure of the block storage network to the guest operating system also poses security risks.  |
| Computing Force Network Requirements Derivation | The goal is to achieve bare metal provisioning and management as elastic as virtual machines: 1. Bare metal servers are fully automatically provisioned. Through the console self-service application, functions such as automatic image installation, network configuration, and cloud disk mounting can be completed without manual intervention. 2. It is fully compatible with the cloud disk system of the virtualization platform. Bare metal can be started from the cloud disk without operating system installation, which meets the requirements of elastic storage. 3. It is compatible with the virtual machine VPC network and realizes the intercommunication between the bare metal server and the virtual machine network. |
| Reference Implementation |  A DPU card needs to be installed on a bare metal server, and the network ports and disk devices of a bare metal instance are all provided by the DPU. The management, network, and storage-related components of the cloud platform run on the DPU. The management module is responsible for the life cycle management of bare metal instances, the network module is responsible for the realization of bare metal virtual network ports and the forwarding of network flows, and the storage module is responsible for the realization of bare metal cloud disks and the termination of the storage protocol stack. In this scenario, the distribution and management process of bare metal is as follows: 1. Select the bare metal flavor through the cloud platform API or UI interface, and create a bare metal instance; 2. The conductor component of the cloud platform initializes the bare metal instantiation process, calls the management module running on the DPU, and completes the configuration of the bare metal instance; 3. The cloud platform creates a virtual network port and initializes the backend of the virtual network port on the DPU. Bare Metal obtains the vNIC through the standard virtio driver after startup. At the same time, the cloud platform synchronizes the network port information to the SDN controller, and the SDN controller sends the flow table to the vSwitch on the DPU of the bare metal node.In this way, the network interworking between bare metal and other instances can be realized; 4. The cloud platform creates a cloud disk, and connects to the remote block storage system on the DPU through a storage protocol stack such as iSCSI. Finally, it is provided to the bare metal instance as a disk through a backend such as NVMe or virtio-blk. |
| Proposal of Technology development and open-source work | 1. Research the decoupling scheme of cloud platform components and DPU hardware drivers, so that different cloud vendors can more efficiently deploy cloud platform software components to DPUs of different vendors; 2. Explore the research of NVMe-oF storage network protocol stack to provide high-performance cloud disk services. |
5. Next Step
This article analyzes the popular definitions, main capability types, service models, technical fields, application scenarios, etc. of the computing force network. In order to further refine the implementation of the computing force network and provide the industry with a more concrete computing force network reference, we plan to rely on the requirement and architecture sub-working group of the CFN WG to further complete the classification of application scenarios and select key application scenarios among them. Based on the selected scenarios, we will sort out the basic functions of the computing force network architecture and collaborate with other CFN WG sub-working groups to form specific scenario solutions.
6. Events about CFN
Event of Computing Force Network-related Standards Organizations
- In February 2019, the Internet Research Task Force (IRTF) began to incubate CFN in the COIN (Computing In Network) research group, and is committed to researching the deep integration of computing and networks to improve network, application performance and user experience.
- In August 2019, the Broadband Forum (BBF) launched the "Metro Computing force network (TR-466)", which mainly studies the scenarios and requirements of computing force networks in metropolitan area networks.
- In November 2019, the International Internet Engineering Task Force (IETF) released a series of personal papers on Computing First Network, focusing on computing force routing protocols. China Mobile took the lead in promoting core documents and technologies such as requirements, architecture, and experiments in the IETF, and jointly held a Side meeting on the key technology of computing force-aware network, namely CFN which is computing-first network.
- Beginning in 2019, ITU-T established the project M.rcpnm: Requirements for Computing Power Network Management in the SG2 group, which mainly studies the functional architecture and functional requirements of computing force network operation and management, including configuration management, fault management and performance management; In the SG11 group, the formulation of the Q.CPN standard (signaling requirements for the computing force network) and the Q.BNG-INC standard (signaling requirements for the border gateway of the computing force network) were initiated; In the SG13 group, the computing force network architecture and computing force-aware network related technologies have promoted the formulation of the Y.CPN-arch standard and the Y.CAN series of standards.
- In August 2019, the China Communications Standards Association (CCSA), China Mobile, China Telecom, and China Unicom jointly led the approval of the "computing force network requirements and architecture" research project in TC3, and output a series of technical requirements and Research topics (computing force network-overall technical requirements, computing force network-controller technical requirements, computing force network-trading platform technical requirements, computing force network-identification analysis technical requirements, computing force network-routing protocol requirements, computing force network requirements and architecture, computing force network capability exposure research).
- In May 2020, the European Telecommunications Standards Institute (ETSI) completed the project approval of NFV support for network function connectivity extensions (NFV-EVE020) in the NFV ISG, based on the Content Forwarding Network (CFN), to study the functional connection expansion solution of the network that combines NFV computing and network integration.
- In July 2022, China Mobile Research Institute completed the project approval of the "Cloud Computing-Functional Requirements for Computing Force Resource Abstraction" standard in ITU-T SG13. Facing the characteristics of heterogeneity and diversity of computing force resources under the background of computing force networks, it proposed the concept of computing force resource abstraction, and focus on the characteristics, functional requirements and end-to-end business scenarios of computing power resource abstraction.
- In February 2023, the China Mobile Research Institute completed the project approval of the "Overall Requirements for Cloud Computing-Oriented Computing Power Resource Abstract Model" standard in CCSA, focusing on the unified architecture requirements of computing force abstraction, programming model and paradigm requirements of computing force abstraction, computing force abstraction model requirements, runtime requirements, cross-architecture compilation requirements, and also the collaboration requirements with computing force management platforms, etc.
- In March 2023, China Mobile promoted the establishment of the "computing force routing" working group in the International Internet Standardization Organization (IETF), which will be responsible for the project establishment and formulation of computing force routing related standards.
Industrial Progress of Computing Force Network
- In June 2021, the IMT-2030 (6G) Promotion Group released the white paper "6G Overall Vision and Potential Key Technologies", listing the computing force-aware network as one of the ten potential key technologies of 6G.
- In September 2019, the Edge Computing Consortium and the Network 5.0 Alliance were jointly established, and the computing force network is regarded as an important direction for future network development.
- In June 2022, China Academy of Information and Communications Technology established a computing force service phalanx to accelerate the innovation and development of computing force service core technologies and build a new industry form of computing force service.
- In June 2022, the Cloud Computing Standards and Open Source Promotion Committee began to conduct research on the trusted computing force standard system, and successively output the general scenarios and overall framework of computing force services, as well as the general technical capability requirements for trusted computing force services-computing force scheduling.
Open source progress of Computing Force Network
- In August 2022, OpenInfra Days China was held in China. The computing force network working group led by China Mobile was announced in OIF (Open Infrastructure Foundation) to share computing force network related technologies and development of open source fields, and discuss the follow-up work plan of the Computing Fower Network Working Group.
Computing Force Network related White Papers
- In November 2019, China Mobile released the "White Paper on Computing Power Aware Network Technology", which introduced the background, requirements, system architecture, key technologies, deployment application scenarios and key technology verification of Computing-aware Networking (CAN) to the industry for the first time.
- In November 2019, China Unicom released the "Computing Force Network White Paper", expounding views on future computing force business forms, ways of platform operation, and network enabling technologies.
- In October 2020, China Unicom released the "White Paper on Computing Force Network Architecture and Technology System", combining the latest policy guidance such as new infrastructure and possible business model innovations in the IPv6+ era. This paper expounds the architecture design, functional model, interlayer interfaces and key technologies of each functional layer of China Unicom's computing force network, and looks forward to the application and deployment of computing force network in combination with several scenarios.
- In March 2021, China Unicom released the "White Paper on Unified Identification and Service of Heterogeneous Computing Force", which elaborates on the development of the industry in the fields of computing force resource management, business modeling, and service capability building.
- In March 2021, China Unicom released the "White Paper on the Evolution of Cloud-Network Convergence to Computing-Network Integration Technology", which elaborated on the technical paths and key capabilities of the evolution from cloud-network integration to computing-network integration for industry development, aiming to promote the deep integration of network and computing, and build a new pattern of future-oriented integrated computing and network services.
- In March 2021, China Unicom released the "Cube-net3.0 Network Innovation System White Paper", which describes the architecture, technical system, technical and service features that can support the new generation of digital infrastructure including computing force networks.
- In November 2021, China Mobile released the "Computing Power Network White Paper", which systematically explained the background, core concepts, application scenarios, development paths and technological innovation of computing force network, and put forward the vision of "network everywhere, computing force everywhere, and intelligence everywhere".
- In November 2021, China Mobile released the 2021 edition of the "Computing Power-Aware Network (CAN) Technical White Paper", which mainly studies the architecture, key technologies and challenges faced by the computing force-aware network. It Explores in fields such as computing force-aware network architecture, computing force measurement, computing force awareness, computing force routing, and computing force management.
- In November 2021, China Mobile released the "NGOAN Intelligent Optical Access Network White Paper", which mainly expounded the thinking and latest achievements on the development of the next-generation optical access network, which can be used as the foundation of the computing power network providing Gigabit optical network. It can be used to build a new information service system of "connection + computing force + capability" and provide committed access connection services.
- In December 2021, China Unicom released the "China Unicom Computing Force Network Practice Case". It describes in detail the application and effect of Unicom Provincial Company's technical solutions such as computing force network resource awareness, network slicing, cloud & network & security integrated service, and all-optical computing force network in specific scenarios.
- In May 2022, China Unicom released the "White Paper on Programmable Service of Computing Power Network", which elaborates on the fields of programmable service of computing force network, SIDaaS technology system, platform design and implementation mechanism, etc. for the development of the industry. It aims to promote Unified orchestration and programmable scheduling of computing force, service and network, empowering the future-oriented "big connection + big computing" digital information infrastructure development.
- In June 2022, China Mobile released the 2022 edition of the "Computing Force Network Technology White Paper". Based on past research results and combining with the latest policy, industry, and standard developments, it looked forward to the ten major technical development directions of the computing power network, and expounded the technical system and technical path of the computing force network.
- In August 2022, China Mobile released the "White Paper on Prospects for Network Architecture and Technical System of Computing and Network Integration", which proposed the design principles, definitions, characteristics and system architecture of computing and network integration from the perspective of network architecture and technological innovation, and used this as a basis to further expounded the key technologies and development prospects of computing-network integration.
- In October 2022, China Unicom released the "White Paper on All-optical Bases in the Computing Force Era", which defined five key features of all-optical bases in the era of computing force. It gives the development directions of all-optical base, in terms of technological evolution, architectural layout and application scenario innovation, from the three dimensions of all-optical city, all-optical hub, and "east data computing in west" respectively.
- In November 2022, China Mobile released the "White Paper on Computing Force Native for Intelligent Computing", proposing the concept of computing force native for the ecological isolation problem in the field of intelligent computing. It systematically expounded the definition and connotation, technical architecture, evolution path, key technologies and other aspects of the computing force native, in order to solve the problem of ecological isolation of large-scale, ubiquitous and diverse heterogeneous computing resources, and realize the seamless cross-architecture migration of applications.
- In December 2022, China Mobile released the "White Paper on the Computing force network Brain", positioning the Computing force network Brain as the "intelligent center" of the entire computing force network system, the core of the computing force network orchestration management layer, and the key to the symbiotic development of the computing force network system. China Mobile proposes to achieve the vision of "the diversified computing force can be deployed ubiquitously, the ultimate network can be intelligently scheduled, computing force network resources can be globally optimized, and computing force network capabilities can be integrated into one supply", aiming to build a computing force network brain that integrates data and intelligence in stages and finally build a complete computing force network brain ecosystem.
7. Reference
- 《中国算力发展指数白皮书》, "China's Computing Force Development Index White Paper"
- 《中国算力发展指数白皮书2022年》, "China's Computing Power Development Index White Paper 2022”
- 《高性能计算云白皮书定稿》,“High Performance Computing Cloud White Paper Finalized”
- 《中国联通算力网络白皮书》,“China Unicom Computing Power Network White Paper”
- 《算力网络架构与技术体系白皮书》,“White Paper on Computing Force Network Architecture and Technology System”
- 《算力网络技术白皮书》,“Computing Force Network Technology White Paper”
- https://blog.csdn.net/ustc_dylan/article/details/121785732