5.6 KiB
Intuitive visualization for test comparison ==========================================
Blueprint: https://blueprints.launchpad.net/refstack/+spec/results-visualization Storyboard: https://storyboard.openstack.org/#!/story/111
Result comparison is the very essence of refstack. This spec lays out the basic design objectives, comparison matrix and wire-frames for the initial visualization between cloud test runs. The display of this information must make it simple for users to map their cloud interoperability to other clouds.
Note: Positive results only for refstack public site. We will still handle negative/skip use cases.
Problem description
Refstack collects substantial amounts of detailed raw data in the form of passed test results. Individually, these tests provide little insight about cloud interoperability; consequently, restack must provide a way to group results (likely capabilities) and contract with other posted test results.
Specific Items that Need Visualization
- Comparison of results against:
-
- Core Test List ("am I core?")
- Universe of Tests ("close to 100%?")
- Other's runs ("do I interoperate?")
- Previous runs ("did I improve?")
To make it easier to determine, results should follow the capabilities groups rather than individual tests. Users should be able to drill down into a capability to look at the test detail.
Note about Capabilities versus Tests: In DefCore, capabilities are tracked as the definition of "core." Each capability has a defined set of tests. For a core capability to be considered as "passed," all of the tests in that capability must pass. Since we do not track "failed" as a state, a non-passing test simply makes the whole capability not passing.
General Visualization: Tristate ----------------------------
The general approach is to focus on _deltas from other sets rather than showing the actual results. This means that visualizations will be more about what's different or changed. The preferred tool will be the "tristate" graph: http://omnipotent.net/jquery.sparkline/#s-about.
- For consistency, users should expect that:
-
- +1 = good, match
- 0 = ok, no match (run is advantaged over reference/core)
- -1 = bad, missing functionality
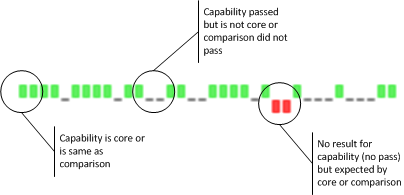
There are two consistent but slightly different ways that we will use tri-state:
- 1) comparing to core tests with a goal of showing compliance
-
- +1 = passed a core test or capability
- 0 = passed a non-core test or capability
- -1 = did not pass a core test or capability (this is the same as "not-reported")
- 2) compare to other tests with a goal of showing interoperability
-
- +1 = passed in both samples
- 0 = passed in subject but not in reference (subject is advantaged)
- -1 = not passed in subject but did in reference (subject is disadvantaged)
An example rendering would lock like this:
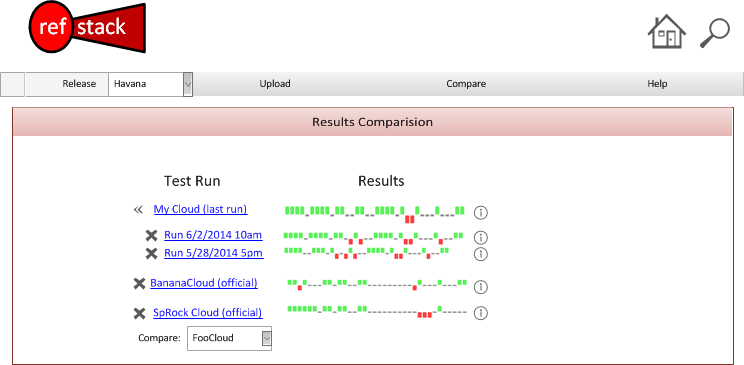
Important Design Note: All tristate graphs must use the same ordered capability/test list to ensure that results are easily to compare visually. The purpose of the tristate is to help quickly find outliers not perform detailed comparison. Drill downs will be used to resolve specific differences.
Detailed Visualization: Drill Down ----------------------------
We will expand the capabilities level tristate in the detailed visualization but still retain the tristate meanings with specific tests. In the drill down, the user will see the original tristate graph above a table with the capabilities list (order preserved) by rows. In each row, the following columns: * the name of the capability * a tristate will visualize the individual test results using the same +1/0/-1 semantics * a simple list of the -1 tests
Usability Note: The name of the test/capability should be included as a hover.
Alternatives
There are several other approaches to visualize this information including shaded table cells and spider charts. This would be acceptable alternatives; however, the tristate chart is compact, very simple to use and highly intuitive for comparing result sets.
It would be possible to use tristate shapes (circle, open circle, square) to reflect the same data on tables.
Data model impact
Likely none; however, depending on the complexity of the queries, it may be necessary to create intermediate tables to to summarize capabilities from test results per run to improve performance.
If new models are needed, this spec should be updated with the design. At this time, we assume that the collection does not require an intermediate model.
Specification for the method
These are read-only reports and should use GETs.
The URL path should match the other UI paths with then following pattern:
Compare against previous results: HTML response: GET /[refstack base]/compare/[release]/[cloud id]
Compare against other clouds: HTML response: GET /[refstack base]/compare/[release]/[cloud id]?to=[other 1]|[other 2]
JSON response same as HTML but with .json
Security impact
None. These are open reports.
Notifications impact
None.
Other end user impact
None.
Developer impact
None.
Assignee(s)
TBD
Work Items
- Spec & Mock
- CSS & HTML Frame
- Data Collection
- Connect Data into UI Page
Dependencies
Sparklines JS libraries: http://omnipotent.net/jquery.sparkline/#s-about
Documentation Impact
Need to document screen and drill down expectation.
References